React Fiber 완전 정복
이번 포스팅에서는 React의 심장이라 할 수 있는 Fiber 아키텍처에 대한 이야기를 해보려고 한다.
필자가 React를 처음 접했을 때, "Fiber" 라는 단어는 면접 단골 질문 정도로만 인식되었다. "React의 렌더를 위해 작업 단위를 나눠서 처리"라는 한 줄짜리 정의를 외우고, 그게 전부인 줄 알았다. 하지만 실제로 React의 소스코드를 들여다보기 시작하면서, Fiber가 단순한 개념이 아니라 React 렌더링의 모든 것을 관장하는 런타임 아키텍처라는 사실을 깨닫게 되었다.
그때 React 소스코드를 처음 열었을 때의 충격은 아직도 잊을 수 없다. "이게... 다 뭐지?" 싶었다.
이 글에서는 "Fiber가 뭐예요?"라는 질문에 "작업 단위를 나눠서 처리하는 거요"라고 대답하는 수준을 넘어, Fiber가 왜 탄생했고, 어떻게 설계되었으며, 그 구조가 React의 Concurrent Features를 어떻게 가능하게 만드는지까지 깊이 있게 파헤쳐 보려 한다.
왜 Fiber가 등장했을까?
이 질문에 답하려면 먼저 Fiber 이전의 세상, 즉 React 15까지 사용되던 Stack Reconciler가 어떤 문제를 가지고 있었는지 이해해야 한다.
Stack Reconciler는 이름 그대로 재귀(recursive) 호출 기반의 재조정 엔진이었다. 컴포넌트 트리를 위에서 아래로 재귀적으로 순회하면서, 한 번 렌더링을 시작하면 전체 트리를 끝까지 처리해야만 멈출 수 있었다. 이것은 마치 전화 통화 중에 상대방이 말을 끝낼 때까지 절대 끊을 수 없는 것과 같은 상황이었다. (상대방이 3시간짜리 인생 상담을 시작했는데 중간에 끊을 수 없다고 생각해보라. 끔찍하다.)
Stack Reconciler은 구체적으로 다음과 같은 한계가 있었다.
- 렌더링 중 중단 불가: 모든 트리를 한 번에 처리해야 했으므로, 복잡한 UI에서는 메인 스레드가 수십~수백 밀리초 동안 점유되었다
- 우선순위 개념 부재: 사용자가 버튼을 클릭하든, 백그라운드 데이터가 갱신되든, 모든 업데이트가 동일한 방식으로 처리되었다
- 애니메이션/제스처 대응 어려움: 60fps를 유지하려면 한 프레임당 약 16ms 안에 모든 작업이 끝나야 하는데, 재귀 렌더링은 이를 보장할 수 없었다
- 에러 발생 시 전체 앱 중단: 컴포넌트 트리 어딘가에서 에러가 발생하면 전체 앱이 멈추는 문제가 있었다
이러한 한계를 극복하기 위해 React 팀은 작업을 쪼개고, 우선순위를 매기고, 필요하면 중단하고 재개할 수 있는 새로운 실행 모델을 고민했다. 그리고 그 결과물이 바로 React Fiber인 것이다.
Andrew Clark가 작성한 react-fiber-architecture 문서는 이 설계의 핵심 사상을 담고 있으며, Fiber를 이해하는 데 가장 중요한 참고 자료다. (이 문서를 작성하고 얼마 안 되어 React 팀에 합류한 것으로 보인다.)
Stack vs Fiber
그렇다면 Stack Reconciler와 Fiber Reconciler는 코드 수준에서 어떻게 다른 것일까?
재귀 기반의 Stack Reconciler
function renderComponent(component) {
const element = component.render();
element.props.children.forEach(child => renderComponent(child)); // 재귀 호출
}Stack 방식은 이렇게 자식 컴포넌트를 만나면 즉시 재귀 호출로 들어간다. 이 방식의 문제는 JavaScript의 콜 스택(call stack)에 직접 의존한다는 점이다. 재귀 호출이 깊어지면 콜 스택에 프레임이 쌓이고, 이 모든 프레임이 해소될 때까지 브라우저의 메인 스레드는 다른 일을 할 수 없다.
쉽게 말해, 콜 스택이 비워질 때까지 브라우저는 꼼짝도 할 수 없는 상태가 되는 것이다.
위 영상을 보면 Stack Reconciler가 렌더링하는 동안 메인 스레드가 완전히 블로킹되는 모습을 확인할 수 있다.
반복 기반의 Fiber Reconciler
Fiber는 재귀를 반복(iterative loop) 으로 대체했다. 콜 스택 대신 자체적인 가상 스택을 메모리 위에 구현한 것이다. 각 Fiber 노드가 곧 하나의 "스택 프레임"이 되며, 이 노드들은 JavaScript 객체(힙 메모리)에 존재하기 때문에 언제든 중단하고 나중에 다시 이어갈 수 있다.
function performWork(deadline) {
while (nextUnitOfWork && deadline.timeRemaining() > 5) {
nextUnitOfWork = performUnitOfWork(nextUnitOfWork);
}
requestIdleCallback(performWork); // 나눠서 실행
}위 코드는 Fiber의 초기 개념 모델을 보여준다. 핵심은 while 루프 안에서 한 번에 하나의 작업 단위(unit of work)만 처리하고, 시간이 부족하면 루프를 빠져나와 브라우저에게 제어권을 돌려준다는 것이다.
(초기에는 requestIdleCallback을 활용하는 방식이었지만, 실제 React는 이를 사용하지 않는다. 이유는 뒤에서 자세히 다룬다.)
Fiber 방식에서는 렌더링 중에도 사용자 이벤트(버튼 클릭, 타이핑 등)에 즉시 반응할 수 있다. 작업을 잘게 쪼개 실행하기 때문에, 브라우저가 숨 쉴 틈이 생기는 것이다.
두 방식의 차이를 직접 체험해보고 싶다면 여기를 클릭하면 된다. Stack Reconciler와 Fiber Reconciler의 동작 차이를 눈으로 확인할 수 있다.
이것이 바로 Andrew Clark이 문서에서 강조한 Fiber의 핵심 목표다.
- 작업을 일시 중지하고 나중에 다시 돌아올 수 있다
- 서로 다른 유형의 작업에 우선순위를 부여할 수 있다
- 이전에 완료된 작업을 재사용할 수 있다
- 더 이상 필요 없는 작업을 중단할 수 있다
Fiber Node 내부 구조
여기까지 읽으면 자연스럽게 떠오르는 질문이 하나 있다. "그래서 Fiber 노드는 내부적으로 어떻게 생겼는가?"
React 팀은 Fiber의 내부 구현에 대한 공식 문서를 별도로 제공하지 않고 있다. 하지만 Andrew Clark의 react-fiber-architecture 문서와 실제 React 소스코드(ReactFiber.js)를 통해 그 구조를 파악할 수 있다.
Fiber 노드를 필자는 작업 지시서(Work Order) 에 비유하고 싶다. 공장에서 제품을 조립할 때, 각 작업 지시서에는 "이 부품이 어떤 종류인지", "어떤 재료를 사용하는지", "다음에 어떤 작업을 해야 하는지", "우선순위는 어떤지"가 적혀 있다. Fiber 노드도 마찬가지다.
ReactElement와 FiberNode
Fiber를 이해하려면 먼저 ReactElement와 FiberNode를 구분해야 한다. 이 둘은 자주 혼동되지만 전혀 다른 존재다.
// ReactElement — React.createElement()가 반환하는 가벼운 객체
export interface ReactElement {
type: string | Function; // 문자열(HTML 태그) 또는 함수(컴포넌트)
props: {
[key: string]: any;
children: ReactElement[];
};
key: string | null;
ref: any;
_owner: FiberNode | null;
}ReactElement는 UI의 설계도에 불과하다. "이런 컴포넌트를 이런 props로 렌더링해달라"는 요청서일 뿐, 실제 렌더링 로직이나 상태는 담고 있지 않다.
반면 FiberNode는 이 설계도를 바탕으로 React가 내부적으로 생성하는 런타임 작업 단위다. ReactElement에는 없는 tag, stateNode, child/sibling/return, memoizedState, updateQueue, lanes 같은 필드들이 여기에 존재한다.
React가 ReactElement의 type을 보고 FiberNode를 생성할 때, tag 값이 결정된다.
type이 함수이고prototype.isReactComponent가 있으면 →tag = ClassComponent(1)type이 함수이면 →tag = FunctionComponent(0)type이 문자열("div"등)이면 →tag = HostComponent(5)
tag는 FiberNode의 종류를 나타내는 숫자 상수다. ReactWorkTags.js에 정의되어 있으며, FunctionComponent(0), ClassComponent(1), HostRoot(3), HostComponent(5), HostText(6) 등 약 25가지 이상의 태그가 존재한다. React는 이 tag 값을 기반으로 beginWork에서 어떤 처리 로직을 실행할지 결정하는 것이다.
type은 재조정(reconciliation) 과정에서 핵심적인 역할을 한다. React가 이전 렌더링의 Fiber와 새 엘리먼트를 비교할 때 가장 먼저 확인하는 것이 바로 type이다. (이 값은 ReactElement에서 FiberNode로 그대로 전달된다.)
- 이전에도
div였고 이번에도div라면, React는 해당 Fiber 노드를 재사용하여 props만 업데이트한다 - 이전에는
div였는데 이번에는span으로 바뀌었다면, React는 기존 Fiber를 버리고 새 Fiber를 생성한다
key 역시 ReactElement에서 FiberNode로 전달되는 값으로, 주로 리스트(배열) 렌더링 시에 사용된다. key가 없으면 React는 리스트 아이템의 순서가 변경되었을 때 어떤 아이템이 어디로 이동했는지 정확히 알 수 없다. 이로 인해 불필요한 DOM 조작이 발생하거나, 컴포넌트의 내부 상태가 의도치 않게 유지 또는 소실될 수 있다.
child, sibling, return
React Fiber가 재귀 대신 반복을 사용할 수 있는 비밀이 바로 여기에 있다.
function 부모() {
return [<자식1/>, <자식2/>];
}child는 컴포넌트의 render가 반환한 첫 번째 자식 요소를 가리킨다. 위 예제에서는 <자식1/>이 해당된다. sibling은 동일한 부모를 가진 다음 형제 요소를 의미한다. <자식1/>의 sibling은 <자식2/>이다. return은 현재 Fiber 노드의 처리가 끝난 뒤 되돌아갈 부모 Fiber를 가리킨다. <자식1/>과 <자식2/>의 return은 모두 부모이다.
이 세 필드가 만들어내는 구조는 단일 연결 리스트(Singly Linked List) 형태의 트리다. 일반적인 트리 구조에서는 자식 배열(children[])을 두는 것이 직관적이지만, Fiber는 의도적으로 이를 피했다.
왜일까? 배열 기반의 자식 구조에서는 순회를 위해 인덱스를 관리해야 하고, 중간에 중단했다가 재개할 때 "어디까지 처리했는지"를 별도로 추적해야 한다. 반면 linked list 구조에서는 현재 노드의 참조만 기억하면 언제든 이어서 순회할 수 있다. 이것이 Fiber가 중단과 재개를 자연스럽게 지원할 수 있는 구조적 기반인 것이다.
React는 이 구조를 기반으로 깊이 우선 탐색(DFS) 순서로 노드를 순회한다. child를 따라 내려가고(beginWork), 리프 노드에 도달하면 sibling을 확인하고, 형제가 없으면 return을 따라 올라가는(completeWork) 방식이다.
pendingProps와 memoizedProps
pendingProps는 해당 Fiber가 처리를 시작할 시점에 전달된 새로운 props를 의미하며, memoizedProps는 이전 렌더링에서 처리가 완료된 이전 props를 나타낸다.
이 두 값이 동일하다면, React는 "이 컴포넌트에는 변경이 없다"고 판단하여 이전 렌더링 결과를 그대로 재사용할 수 있다. 이것이 바로 bailout 최적화의 핵심 메커니즘이다.
마찬가지로 memoizedState는 해당 Fiber의 훅(hooks) 상태를 저장하며, updateQueue는 아직 처리되지 않은 상태 업데이트(setState 호출들)를 연결 리스트로 관리한다.
stateNode
stateNode는 Fiber 노드가 가리키는 실제 인스턴스를 참조한다.
- HostComponent(div, span 등)의 경우: 실제 DOM 노드
- ClassComponent의 경우: 클래스 인스턴스
- HostRoot의 경우: FiberRoot 객체
이 필드는 Fiber의 가상 세계와 브라우저의 실제 DOM을 연결하는 다리 역할을 한다.
더블 버퍼링: current 트리와 workInProgress 트리
Fiber를 이해하는 데 있어 빠뜨릴 수 없는 핵심 개념이 바로 **더블 버퍼링(Double Buffering)**이다.
이 개념을 이해하기 위해 게임 그래픽을 떠올려보자. 게임에서 화면을 그릴 때, 현재 화면에 직접 픽셀을 그리면 반쯤 그려진 프레임이 사용자에게 보이는 화면 깜빡임(tearing) 현상이 발생한다. 이를 방지하기 위해 게임 엔진은 두 개의 버퍼를 사용한다. 하나의 버퍼에 다음 프레임을 완전히 그린 후, 완성되면 화면에 표시되는 버퍼를 한 번에 교체하는 것이다.
React Fiber도 정확히 같은 전략을 사용한다.
currentFiber.alternate === workInProgressFiber;
workInProgressFiber.alternate === currentFiber;current 트리는 현재 화면에 반영되어 있는 Fiber 트리. 사용자가 보고 있는 UI의 상태를 나타내고, workInProgress 트리는 다음 렌더링을 위해 백그라운드에서 준비 중인 Fiber 트리를 나타낸다.
두 트리는 alternate 속성으로 서로를 참조한다. 모든 변경 작업은 workInProgress 트리에서 수행되며, 작업이 완료되면 root.current = finishedWork 한 줄로 트리가 교체된다. 이전의 workInProgress가 새로운 current가 되고, 이전의 current는 다음 렌더링에서 workInProgress로 재활용되는 것이다.
function createWorkInProgress(current, pendingProps) {
let workInProgress = current.alternate;
if (workInProgress === null) {
// 최초 렌더: 새 Fiber를 생성하고 alternate를 연결
workInProgress = createFiber(current.tag, pendingProps, current.key, current.mode);
workInProgress.stateNode = current.stateNode; // DOM 노드는 공유!
workInProgress.alternate = current;
current.alternate = workInProgress;
} else {
// 재렌더: 기존 alternate를 재사용, effect만 초기화
workInProgress.pendingProps = pendingProps;
workInProgress.flags = NoFlags;
workInProgress.subtreeFlags = NoFlags;
workInProgress.deletions = null;
}
// lanes, child, memoizedState 등을 복사
workInProgress.childLanes = current.childLanes;
workInProgress.child = current.child;
// ...
}여기서 핵심을 짚어보자. stateNode(실제 DOM 노드)는 current와 workInProgress 사이에서 공유된다. Fiber 객체를 매번 새로 만드는 것이 아니라, 기존 alternate를 재사용하면서 변경된 필드만 업데이트한다. 이 덕분에 매 렌더마다 가비지 컬렉션(GC) 부담 없이 효율적으로 트리를 구성할 수 있는 것이다.
만약 props나 state에 변경이 없다면? 해당 서브트리를 통째로 건너뛰는 bailout 최적화가 가능해진다. 게임의 더블 버퍼링이 프레임 단위의 최적화라면, Fiber의 더블 버퍼링은 컴포넌트 단위의 최적화까지 가능하게 만드는 것이다.
pendingWorkPriority => Lanes
그렇다면 Fiber는 어떻게 "이 작업이 더 중요하다"는 것을 판단하는 것일까?
expirationTime의 한계
초기 Fiber는 pendingWorkPriority라는 숫자 기반의 우선순위를 사용했고, 이후 expirationTime이라는 단일 숫자로 발전했다. 만료 시간이 가까울수록 높은 우선순위를 의미했는데, 이 방식에는 근본적인 한계가 있었다.
단일 숫자로는 "이 업데이트는 A 그룹에 속하고, 저 업데이트는 B 그룹에 속한다"는 식의 유연한 분류가 불가능했기 때문이다. 예를 들어 사용자 입력과 Transition 업데이트가 동시에 발생했을 때, expirationTime 기반에서는 범위(range) 비교로만 분류할 수 있었고, 특정 업데이트만 선택적으로 처리하는 데 한계가 있었다.
Lane
이 문제를 해결하기 위해 Andrew Clark이 PR #18796에서 도입한 것이 Lane 시스템이다.
Lane을 이해하기 위해 고속도로를 떠올려보자. 고속도로에는 여러 차선(lane)이 있고, 각 차선은 서로 다른 용도를 가진다. 1차선은 추월 차선(긴급), 2차선은 주행 차선(일반), 갓길은 비상용이다. 각 차량(업데이트)은 자신의 성격에 맞는 차선에 배정되고, 고속도로 관리 시스템(스케줄러)은 어떤 차선의 차량을 먼저 통과시킬지 결정한다.
React의 Lane도 이와 같다. 각 업데이트에 비트 하나(lane) 를 할당하고, 비트 연산으로 그룹을 만들고 비교하는 것이다.
// 각 업데이트는 하나의 lane(단일 비트)을 가진다
const SyncLane = /* */ 0b0000000000000000000000000000010;
const InputContinuousLane = /* */ 0b0000000000000000000000000001000;
const DefaultLane = /* */ 0b0000000000000000000000000100000;
const TransitionLane1 = /* */ 0b0000000000000000000000100000000;
const IdleLane = /* */ 0b0001000000000000000000000000000;
// 배치(batch)는 여러 비트의 OR 조합이다
const SyncUpdateLanes = SyncLane | InputContinuousLane | DefaultLane;
// 특정 lane이 batch에 포함되는지 확인은 단순 비트 연산
const isIncluded = (lane & lanes) !== 0;총 31개의 lane이 31비트 정수에 들어가도록 설계되어 있는데, 이는 V8 엔진의 SMI(Small Integer) 최적화를 활용하기 위함이다. 31비트 이하의 정수는 V8에서 포인터 태깅으로 처리되어 힙 할당 없이 스택에서 직접 연산할 수 있다. 주요 lane의 우선순위는 낮은 비트일수록 높다.
이 구조 덕분에 React는 비트 연산 한 번으로 어떤 작업을 먼저 처리할지 결정할 수 있게 되었다. getNextLanes() 함수는 pendingLanes에서 가장 높은 우선순위의 lane 그룹을 골라내고, 중단된(suspended) lane은 건너뛰며, 데이터를 받은(pinged) lane은 우선 재시도하는 등의 정교한 스케줄링이 가능해진 것이다.
또한 기아 상태(starvation) 방지를 위해 각 lane에 만료 시간이 부여된다. Sync/InputContinuous는 250ms, Transition은 5000ms가 지나면 expiredLanes에 추가되어 동기적으로 강제 처리된다. 아무리 우선순위가 낮아도 영원히 무시당하지는 않는다는 뜻이다. (우선순위가 낮다고 영원히 무시당하면 그건 우선순위 시스템이 아니라 차별 시스템이다.)
Fiber의 output
여기까지 Fiber의 구조를 살펴봤다면, 이제 궁금해지는 것이 하나 있다. 이 Fiber 노드들이 어떻게 실제 DOM으로 변환되는 것일까?
output은 실제 DOM에 적용될 수 있는 구체적인 DOM 노드 정보를 의미한다. 여기서 중요한 구분이 있다.
// 사용자 정의 컴포넌트 — output 없음
function 아바타() {
return <img src="profile.jpg" />;
}
// 호스트 컴포넌트 — output 생성
<img src="profile.jpg" />
<div className="프로필" />호스트 컴포넌트(div, span, img 등)만 실제 DOM 노드를 생성한다. 브라우저는 <아바타/>가 뭔지 모른다. 사용자 정의 컴포넌트는 추상화된 개념이기 때문에, 결국 호스트 컴포넌트로 분해되어야 브라우저가 이해할 수 있다.
이 과정을 좀 더 구체적으로 살펴보자.
function 프로필() {
return (
<div className="프로필">
<아바타 />
<유저정보 />
</div>
);
}
function 아바타() {
return <img src="profile.jpg" alt="프로필" />;
}
function 유저정보() {
return (
<div>
<h2>홍길동</h2>
<p>개발자</p>
</div>
);
}이 컴포넌트들이 만들어내는 Fiber 트리와 output의 관계는 다음과 같다.
프로필 (출력: 없음, 컴포넌트 함수)
│
└─► div.프로필 (출력: <div class="프로필">...</div>)
│
├─► 아바타 (출력: 없음, 컴포넌트 함수)
│ │
│ └─► img (출력: <img src="profile.jpg" alt="프로필">)
│
└─► 유저정보 (출력: 없음, 컴포넌트 함수)
│
└─► div (출력: <div>...</div>)
│
├─► h2 (출력: <h2>홍길동</h2>)
│
└─► p (출력: <p>개발자</p>)
output 수집은 아래에서 위로 진행된다. 먼저 리프(호스트) 노드에서 DOM이 생성된다.
// 호스트 컴포넌트들이 실제 DOM 정보 생성
img_fiber.output = createDOMElement('img', {
src: 'profile.jpg',
alt: '프로필'
});
h2_fiber.output = createDOMElement('h2', {}, '홍길동');
p_fiber.output = createDOMElement('p', {}, '개발자');그 다음 부모 호스트 컴포넌트가 자식들의 output을 수집한다.
// div 노드가 자식들의 출력을 수집
유저정보_div_fiber.output = createDOMElement('div', {}, [
h2_fiber.output, // <h2>홍길동</h2>
p_fiber.output // <p>개발자</p>
]);
// 최상위 div가 모든 자식 출력을 수집
프로필_div_fiber.output = createDOMElement('div', {className: '프로필'}, [
img_fiber.output, // <img src="profile.jpg" alt="프로필">
유저정보_div_fiber.output // <div><h2>홍길동</h2><p>개발자</p></div>
]);마지막으로, 사용자 정의 컴포넌트는 자식의 output을 그대로 전달한다.
// 사용자 정의 컴포넌트는 자식의 출력을 위로 전달
아바타_fiber.output = img_fiber.output;
유저정보_fiber.output = 유저정보_div_fiber.output;
프로필_fiber.output = 프로필_div_fiber.output;Fiber의 스케줄링
Fiber의 핵심 가치가 "작업을 나눌 수 있다"는 것이라면, 실제로 그 "나누기"를 수행하는 곳은 어디일까? 바로 Work Loop이다.
Work Loop: Fiber 순회의 심장
React의 렌더링은 ReactFiberWorkLoop.js에 정의된 Work Loop에서 시작된다. React는 상황에 따라 두 가지 Work Loop를 사용한다.
// 동기 렌더링: 중단 없이 모든 Fiber를 처리
function workLoopSync() {
while (workInProgress !== null) {
performUnitOfWork(workInProgress);
}
}
// 동시성 렌더링: 시간 제한 내에서 작업을 나누어 처리
function workLoopConcurrent(nonIdle) {
if (workInProgress !== null) {
const yieldAfter = now() + (nonIdle ? 25 : 5);
do {
performUnitOfWork(workInProgress);
} while (workInProgress !== null && now() < yieldAfter);
}
}두 함수의 차이를 주목하라. workLoopSync는 workInProgress가 null이 될 때까지 무조건 돈다. 반면 workLoopConcurrent는 시간 제한을 두고, 시간이 초과되면 루프를 빠져나온다.
여기서 흥미로운 것은 yield 간격의 차이다. Transition이나 Retry 같은 non-idle 작업(사용자가 체감할 수 있는 업데이트) 은 25ms 간격으로 양보하고, idle 작업(사용자가 아무것도 안 하고 있을 때 처리해도 되는 낮은 우선순위 작업) 은 5ms 간격으로 양보한다. non-idle 작업에 25ms를 부여하는 이유는 의도적으로 애니메이션을 약 30fps 수준으로 제한하여, transition 렌더링이 다른 작업을 기아 상태로 만드는 것을 방지하기 위함이다.
performUnitOfWork
performUnitOfWork는 하나의 Fiber 노드를 처리하는 함수다. Fiber 순회의 핵심이 이 함수에 담겨 있다.
function performUnitOfWork(unitOfWork) {
const current = unitOfWork.alternate;
const next = beginWork(current, unitOfWork, renderLanes);
unitOfWork.memoizedProps = unitOfWork.pendingProps;
if (next !== null) {
workInProgress = next;
} else {
completeUnitOfWork(unitOfWork);
}
}beginWork는 현재 노드를 처리하고 첫 번째 자식을 반환한다. 그리고 pendingProps를 memoizedProps로 확정하고 자식이 있으면 자식으로, 없으면 completeUnitOfWork를 호출한다
beginWork
beginWork는 Fiber 노드를 위에서 아래로 순회하며, 각 노드에서 필요한 계산을 수행하는 함수다. ReactFiberBeginWork.js에 정의되어 있으며, 내부적으로 Fiber의 tag에 따라 거대한 switch문으로 분기한다.
function beginWork(current, workInProgress, renderLanes) {
// bailout 체크: props와 context가 변경되지 않았다면 스킵
if (current !== null) {
const oldProps = current.memoizedProps;
const newProps = workInProgress.pendingProps;
if (oldProps === newProps && !hasContextChanged()) {
return bailoutOnAlreadyFinishedWork(current, workInProgress, renderLanes);
}
}
switch (workInProgress.tag) {
case FunctionComponent:
return updateFunctionComponent(current, workInProgress, ...);
case ClassComponent:
return updateClassComponent(current, workInProgress, ...);
case HostComponent:
return updateHostComponent(current, workInProgress, ...);
case SuspenseComponent:
return updateSuspenseComponent(current, workInProgress, ...);
// ... 약 25가지 이상의 케이스
}
}핵심은 맨 위의 bailout 체크다. props와 context가 이전과 동일하다면 bailoutOnAlreadyFinishedWork로 해당 서브트리를 통째로 건너뛴다. 이것이 React의 성능 최적화에서 가장 중요한 경로 중 하나다.
beginWork의 반환값은 첫 번째 자식 Fiber이다. 자식이 있으면 그 자식이 다음 workInProgress가 되고, 없으면(null) completeUnitOfWork로 진입한다.
completeWork
completeWork는 리프 노드에서 시작하여 부모 방향으로 올라가며 작업을 마무리하는 함수다.
function completeUnitOfWork(unitOfWork) {
let completedWork = unitOfWork;
do {
// 1. completeWork로 현재 노드의 작업 마무리 (DOM 생성 등)
completeWork(current, completedWork, renderLanes);
// 2. 형제가 있으면 형제로 이동 (다시 beginWork 시작)
const siblingFiber = completedWork.sibling;
if (siblingFiber !== null) {
workInProgress = siblingFiber;
return;
}
// 3. 형제가 없으면 부모로 올라감
completedWork = completedWork.return;
workInProgress = completedWork;
} while (completedWork !== null);
}completeWork에서 수행하는 주요 작업은 다음과 같다.
- HostComponent의 경우: 실제 DOM 노드를 생성(
createInstance)하고, 자식 DOM들을 append한다. 이미 존재하는 DOM이라면 변경된 props를 수집하여updateQueue에 저장한다. bubbleProperties(): 자식들의 flags를subtreeFlags로 집계한다. 이 정보는 Commit Phase에서 서브트리 스킵 최적화에 사용된다.
순회를 정리하면 이렇다. child를 따라 내려가고(beginWork) -> 리프에서 완료 후 sibling으로 이동 -> 형제가 없으면 return을 따라 올라감(completeWork). 이것이 Fiber의 깊이 우선 탐색 순서인 것이다.
requestIdleCallback을 버린 이유
앞서 Fiber의 개념 모델에서 requestIdleCallback을 사용하는 코드를 보여줬는데, 실제 React는 이를 사용하지 않는다. 그 이유는 명확하다.
- 호출 빈도가 너무 낮다 : 진정한 "유휴 시간(브라우저가 할 일이 없는 시간)"에만 호출되어, 바쁜 페이지에서는 React 작업이 무한정 지연될 수 있다. Dan Abramov도 "requestIdleCallback is called too infrequently to be useful for scheduling React work"라고 언급한 바 있다.
- 브라우저 호환성 문제 : Safari는 오랫동안 이를 구현하지 않았고, 브라우저마다 동작이 달랐다.
- 20ms 상한 : idle deadline의 상한이 있어 React가 원하는 수준의 예측 가능한 타이밍 제어가 불가능했다.
그 다음으로 requestAnimationFrame + 프레임 예산 추정 방식을 시도했지만, React의 작업이 vsync(모니터가 수직 귀선을 완료한 시점에 맞춰 프레임 출력을 동기화하는 기술) 주기에 맞출 필요가 없다는 판단하에 이 역시 폐기되었다.
MessageChannel
최종적으로 React는 MessageChannel을 선택했다.
if (typeof MessageChannel !== 'undefined') {
const channel = new MessageChannel();
channel.port1.onmessage = performWorkUntilDeadline;
schedulePerformWorkUntilDeadline = () => channel.port2.postMessage(null);
} else {
schedulePerformWorkUntilDeadline = () => setTimeout(performWorkUntilDeadline, 0);
}왜 setTimeout이 아닌 MessageChannel일까? setTimeout은 HTML 스펙에 따라 5회 이상 중첩되면 최소 4ms의 지연이 강제된다. 반면 MessageChannel은 이런 제한 없이 다음 이벤트 루프 틱에서 즉시 매크로태스크로 실행된다. 5ms 단위로 작업을 쪼개는 Fiber에게 4ms의 인위적 지연은 치명적이기 때문이다.
(5ms 중 4ms가 대기 시간이라면, 실질적으로 일하는 시간은 1ms뿐이다. 이건 워라밸이 아니라 그냥 밸이다.)
React의 Scheduler 패키지는 내부적으로 두 개의 min-heap(최소 힙) 을 관리한다.
timerQueue (대기실) taskQueue (실행 대기열)
┌──────────────────┐ ┌──────────────────┐
│ 아직 시작 시간이 │ startTime │ 지금 실행 가능한 │
│ 안 된 태스크들 │ ──경과 시──→ │ 태스크들 │
│ │ │ │
│ 정렬: startTime │ │ 정렬: expiration │
│ (빠른 순) │ │ Time (임박한 순) │
└──────────────────┘ └──────────────────┘
taskQueue는 "지금 당장 실행할 수 있는" 태스크들의 큐다. expirationTime(= startTime + timeout)이 작을수록, 즉 만료가 임박할수록 먼저 실행된다. timerQueue는 "아직 실행 시점이 오지 않은" 태스크들의 대기실이다. 현재 시간이 startTime을 넘는 순간 taskQueue로 이동한다.
그렇다면 expirationTime을 결정하는 timeout은 어떻게 정해질까? 각 업데이트의 우선순위(Priority Level)에 따라 고유한 timeout이 부여된다.
우선순위 timeout 만료까지 예시
─────────────────────────────────────────────────────────
Immediate -1ms 즉시 만료 flushSync
UserBlocking 250ms 0.25초 클릭, 입력
Normal 5,000ms 5초 일반 setState
Low 10,000ms 10초 startTransition
Idle ~1,073,741,823ms ~12.4일 오프스크린 렌더링
Immediate는 생성 즉시 만료된다. taskQueue에 들어가자마자 최우선으로 실행되는 것이다. (태어나자마자 만료라니, 좀 서글픈 운명이긴 하다.) UserBlocking의 250ms는 사람이 "반응이 느리다"고 느끼는 임계치(100~300ms)에 맞춘 값이다. 클릭했는데 0.25초 안에 반응이 없으면 사용자는 불쾌해진다. Normal의 5초는 넉넉해 보이지만, 이는 "최악의 경우에도 반드시 처리한다"는 보장이다. 실제로는 앞선 작업이 끝나면 곧바로 실행된다. Idle의 약 12.4일은 사실상 무한이다. 다른 모든 작업이 끝나야 비로소 실행된다. (12일 동안 브라우저를 안 닫고 있을 일은 거의 없으니, 무한이라고 봐도 무방하다.)
이 timeout 값들은 동시에 기아 상태(starvation) 방지 메커니즘이기도 하다. 아무리 우선순위가 낮아도 timeout이 지나면 만료 상태가 되어 강제 실행된다. 높은 우선순위 작업이 계속 들어온다고 해서 낮은 우선순위 작업이 영원히 무시당하는 일은 없는 것이다.
Scheduler의 shouldYieldToHost()는 작업 시작 이후 경과 시간이 frameInterval(기본 5ms, SchedulerFeatureFlags.js에서 정의)을 초과했는지를 확인하여 메인 스레드에 제어권을 돌려줄지 결정한다.
Render Phase와 Commit Phase
지금까지 Fiber의 구조와 스케줄링을 살펴봤다. 이제 이 모든 것이 어떻게 조합되어 실제 UI 업데이트가 이루어지는지 전체 흐름을 정리해보자.
Fiber는 내부적으로 Render Phase와 Commit Phase라는 두 단계를 거친다. 이 분리는 React의 동시성 모델을 가능하게 만드는 핵심 설계인 것이다. Fiber의 작동 흐름을 직접 확인하고 싶다면 아래 이미지를 클릭하면 된다.
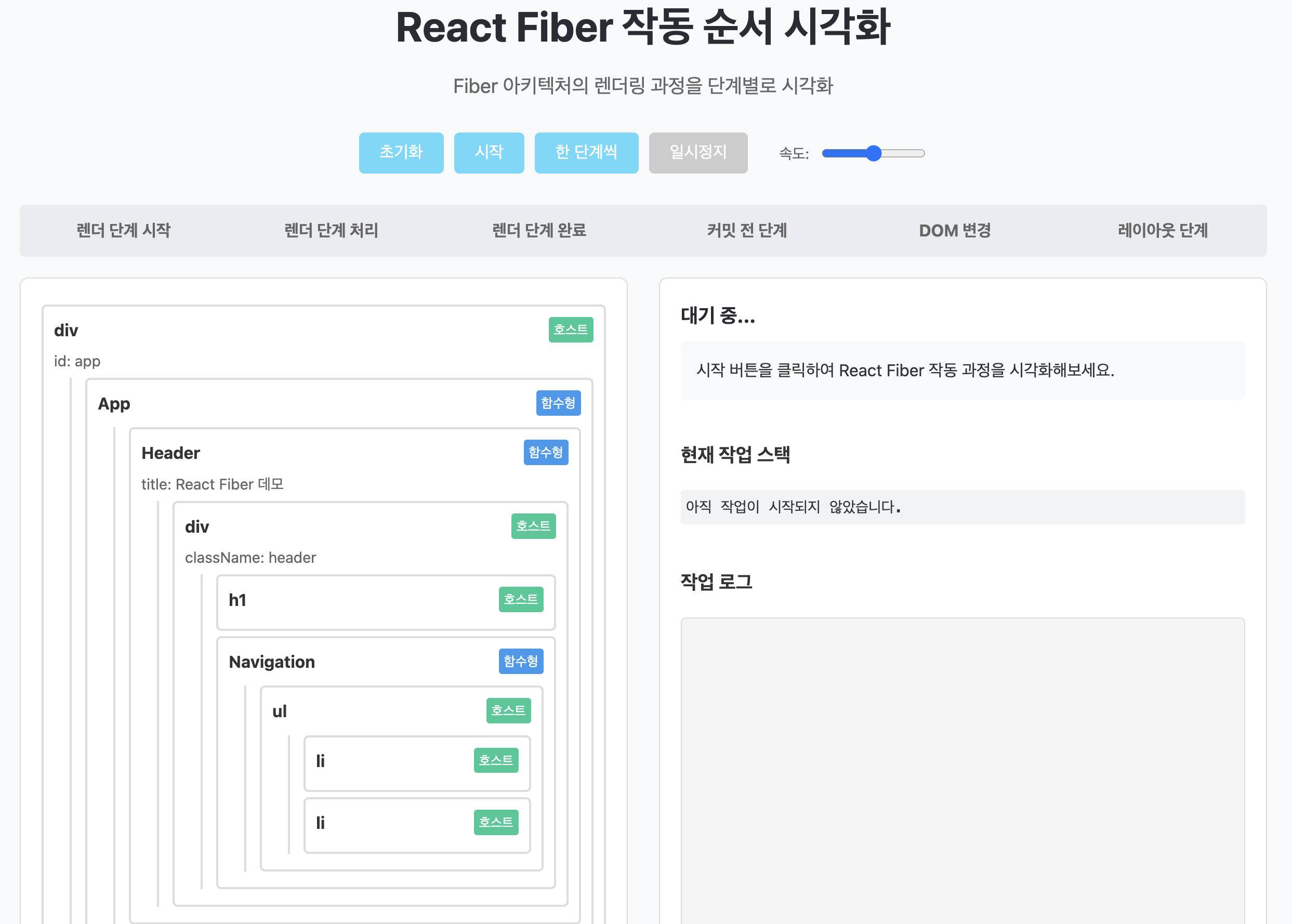
Render Phase
Render Phase는 UI에 어떤 변경이 필요한지 계산하는 단계다. 이 단계에서는 DOM에 실제로 아무런 영향을 주지 않는다. 그리고 가장 중요한 특성은 비동기적으로 중단 및 재개가 가능하다는 것이다.
이 단계는 앞서 살펴본 beginWork와 completeWork 중심으로 동작한다.
beginWork(fiber) 에서는 각 Fiber의 타입(FunctionComponent, ClassComponent, HostComponent 등)에 따라 적절한 로직을 실행한다. 그리고 자식 Fiber 노드를 생성하고 연결한다. props가 이전과 동일하다면 memoization을 활용해 스킵할 수 있다(bailout)
completeWork(fiber) 에서는 DOM 생성 작업이나 effect 정보를 준비한다. 그리고 bubbleProperties()를 통해 자식들의 flags를 subtreeFlags로 집계하고, 부모 방향으로 올라가며 정보를 보완한다
이 단계에서 DOM을 직접 수정하지 않기 때문에, 언제든 작업을 중단하고 나중에 다시 시작하더라도 사용자에게 불완전한 UI가 노출되지 않는다. 이것이 Concurrent 모드의 기반인 것이다.
subtreeFlags
Render Phase에서 각 Fiber에는 어떤 부수 효과(side effect)가 필요한지 비트 플래그로 기록된다. ReactFiberFlags.js에 정의된 주요 플래그를 살펴보자.
Placement: 새 노드를 DOM에 삽입Update: DOM 속성 업데이트 필요ChildDeletion: 자식 노드 삭제 필요Ref: ref 연결/해제 필요Passive: useEffect 콜백 실행 필요Snapshot: getSnapshotBeforeUpdate 실행Callback: 라이프사이클 콜백 실행
이전 React(~16)에서는 firstEffect -> nextEffect -> lastEffect로 연결된 linked list를 사용하여 부수 효과가 있는 Fiber만 모아뒀다. 하지만 이 방식은 언마운트된 Fiber의 참조가 남아 메모리 누수를 일으키는 문제가 있었고, Suspense 같은 새로운 패턴을 효율적으로 처리하기 어려웠다.
React 17부터는 이 effect list를 제거하고 subtreeFlags 방식으로 전환했다(PR #19381). completeWork 단계에서 bubbleProperties()가 자식들의 flags를 부모로 집계한다.
function bubbleProperties(completedWork) {
let subtreeFlags = NoFlags;
let child = completedWork.child;
while (child !== null) {
subtreeFlags |= child.subtreeFlags;
subtreeFlags |= child.flags;
child = child.sibling;
}
completedWork.subtreeFlags |= subtreeFlags;
}이 구조의 가장 큰 장점은 Commit Phase에서 서브트리 전체를 스킵할 수 있다는 것이다. 만약 어떤 Fiber의 subtreeFlags & MutationMask === NoFlags라면, 그 서브트리에는 DOM 변경이 필요한 노드가 전혀 없으므로 통째로 건너뛸 수 있다. 이전의 linked list 방식에서는 불가능했던 최적화다.
Commit Phase
Commit Phase는 Render Phase에서 계산된 변경 사항을 실제 DOM에 반영하는 단계다. 이 단계는 항상 동기적으로 수행되며, 한 번 시작하면 끝까지 중단 없이 실행된다. 사용자가 반쯤 업데이트된 UI를 보게 되는 것을 방지하기 위함이다.
Commit Phase는 내부적으로 다음과 같은 세밀한 순서로 동작한다.
- Before Mutation Phase :
commitBeforeMutationEffects()- DOM이 변경되기 전에 현재 DOM 상태를 읽는다.
getSnapshotBeforeUpdate라이프사이클이 여기서 실행된다. 이 시점에서current트리는 아직 화면의 상태를 나타내므로, DOM의 스크롤 위치나 크기 같은 정보를 안전하게 캡처할 수 있다.
- DOM이 변경되기 전에 현재 DOM 상태를 읽는다.
- Mutation Phase :
commitMutationEffects()- 실제 DOM 조작이 수행되는 단계다. 새 노드 삽입, 기존 노드 수정, 불필요한 노드 삭제가 모두 여기서 일어난다.
componentWillUnmount도 이 시점에 실행되는데, 아직current가 이전 트리를 가리키고 있으므로 이전 상태를 읽을 수 있기 때문이다.
- 실제 DOM 조작이 수행되는 단계다. 새 노드 삽입, 기존 노드 수정, 불필요한 노드 삭제가 모두 여기서 일어난다.
- 트리 교체 :
root.current = finishedWork- 더블 버퍼링의 핵심이다. workInProgress 트리가 current 트리로 승격된다. 이 교체가 Mutation 후, Layout 전에 실행되는 이유가 중요하다.
componentWillUnmount는 이전 트리를 읽어야 하므로 Mutation 단계에서 실행되어야 하고,componentDidMount/componentDidUpdate는 새 트리를 읽어야 하므로 Layout 단계에서 실행되어야 하기 때문이다.
- 더블 버퍼링의 핵심이다. workInProgress 트리가 current 트리로 승격된다. 이 교체가 Mutation 후, Layout 전에 실행되는 이유가 중요하다.
- Layout Phase :
commitLayoutEffects()- DOM 변경이 완료된 후, 새 DOM 상태를 기반으로 하는 작업들이 실행된다.
componentDidMount,componentDidUpdate실행useLayoutEffect콜백 실행- 이 시점에서
current는 이미 새 트리를 가리키므로, DOM을 읽으면 업데이트된 값을 얻을 수 있다
- DOM 변경이 완료된 후, 새 DOM 상태를 기반으로 하는 작업들이 실행된다.
- Passive Effects (비동기)
useEffect의 cleanup과 setup은 별도로 스케줄링되어 비동기적으로 실행된다. 이들은 DOM 변경에 의존하지 않는 부수 효과(데이터 패칭, 이벤트 구독 등)를 처리하기 위한 것이므로, 동기적으로 실행할 필요가 없다. 이를 비동기로 처리함으로써 브라우저가 먼저 화면을 그릴 수 있도록 양보하는 것이다.
Concurrent Features와 Fiber
지금까지 살펴본 Fiber의 모든 설계(더블 버퍼링, Lane 기반 우선순위, 중단 가능한 Work Loop)가 실제로 어떤 사용자 경험을 가능하게 만드는지, React 18 이후의 Concurrent Features를 통해 확인해보자.
useTransition
startTransition(() => setState(...))을 호출하면, 해당 업데이트에는 TransitionLane이 부여된다. 14개의 TransitionLane이 라운드로빈(작업을 순서대로 돌아가며 하나씩 배정하는 방식)으로 할당되어 충돌을 방지한다.
TransitionLane은 SyncLane이나 DefaultLane보다 우선순위가 낮기 때문에, 사용자 입력 같은 긴급 업데이트가 들어오면 transition 렌더링을 중단하고 긴급 업데이트를 먼저 처리할 수 있다. 이 동안 화면에는 current 트리(이전 상태)가 유지되고, transition은 workInProgress 트리에서 백그라운드로 진행된다.
여기서 더블 버퍼링의 가치가 빛난다. 중단된 transition 렌더링은 workInProgress 트리에만 영향을 미치고, 사용자가 보는 화면(current 트리)은 전혀 손상되지 않는 것이다.
isPending 플래그는 이 transition이 아직 완료되지 않았음을 나타내어, 로딩 인디케이터를 보여주는 등의 처리가 가능하다.
useDeferredValue
useDeferredValue(value)는 최초 렌더링에서는 전달된 value를 그대로 반환한다. 이후 렌더링에서 현재 렌더가 긴급한 경우, 이전의 memoized 값을 반환하고 TransitionLane으로 새로운 렌더를 스케줄링한다. 지연된 렌더링은 Transition과 마찬가지로 중단 가능하다
개념적으로는 startTransition과 유사하지만, 업데이트를 디스패치하는 쪽이 아니라 값을 수신하는 쪽에서 적용하는 차이가 있다. 검색 입력란의 텍스트는 즉시 반영하되, 검색 결과 목록의 렌더링은 지연시키는 것이 대표적인 사용 사례다.
Suspense
컴포넌트가 <Suspense> 내부에서 Promise를 throw하면 throwException이 이를 캐치하고 해당 Fiber를 Incomplete로 마킹한다. 그리고 return 체인을 따라 올라가며 가장 가까운 Suspense 경계를 탐색하고, Suspense 경계가 fallback UI를 표시하도록 전환한다. Promise가 resolve되면 markRootPinged로 해당 lane을 ping하고, React가 suspended 서브트리를 다시 렌더링한다
Concurrent 모드에서는 suspended 컴포넌트의 형제(sibling) 노드들을 계속 렌더링할 수 있어, 하나의 데이터 요청이 전체 트리의 렌더링을 차단하지 않는다. 이것이 가능한 이유는 Fiber의 linked list 구조 덕분에 sibling으로의 이동이 자유롭기 때문이다.
Streaming SSR과 Selective Hydration
React 18의 renderToPipeableStream은 Suspense 경계를 활용한다.
- 서버: Suspense 경계가 suspend되면, fallback HTML을 먼저 전송하고 데이터가 준비되면 나중에
<script>태그로 실제 콘텐츠를 스트리밍한다 - 클라이언트 (Selective Hydration): 각 Suspense 경계가 독립적으로 hydration될 수 있다. 사용자가 아직 hydration되지 않은 영역을 클릭하면,
SelectiveHydrationLane을 통해 해당 경계의 hydration을 우선적으로 처리한 뒤 이벤트를 디스패치한다
이 모든 것이 가능한 이유는 각 Suspense 경계가 독립적으로 스케줄링 가능한 Fiber 노드이기 때문이다. 결국 Fiber 아키텍처의 "작업을 나누고, 우선순위를 매기고, 중단/재개할 수 있다"는 핵심 설계가 이러한 기능들의 토대가 되는 것이다.
마치며
이 글에서 다룬 내용을 한 문장으로 요약하면, React Fiber는 재귀를 반복으로 바꾸고, 콜 스택을 힙으로 옮겨, 렌더링을 중단하고 재개할 수 있게 만든 아키텍처다.
이를 위해 linked list 기반의 트리 구조, 더블 버퍼링, Lane 기반 우선순위 시스템, MessageChannel 기반 스케줄러 등 수많은 정교한 설계가 조합되었다. 그리고 이 모든 것은 결국 사용자가 느끼는 UI의 반응성을 극대화하는 것 이라는 목표를 향하고 있다.
물론 Fiber의 내부 구현은 React 버전이 올라갈 때마다 계속 변화하고 있으며, 이 글에서 다룬 내용 역시 특정 시점의 스냅샷에 불과하다. 하지만 "작업을 나누고, 우선순위를 매기고, 중단하고 재개할 수 있다"는 Fiber의 핵심 철학만큼은 앞으로도 변하지 않을 것이라 생각한다.
이 글을 통해 React Fiber가 단순한 면접 키워드가 아닌, React의 모든 기능을 떠받치는 런타임 아키텍처라는 점이 전달되었기를 바란다. 정답은 없지만, 이 글을 읽는 독자분들도 소스코드를 직접 들여다보며 각자만의 이해를 쌓아가기를 바란다.
출처
참고 자료
📚함께 읽으면 좋은 글
상태 관리
2026. 5. 18. · 36 min read
이번 포스팅에서는 상태 관리(State Management) 에 대한 이야기를 해보려고 한다. 라이브러리 비교 글은 아니다. 어떤 도구가 더 좋은지를 가리는 것보다, 상태라는 것을 어떻게 바라보고, 어디에 경계를 그어야 하는지에 대한 감각을 정리하는 글이다. 요즘 AI 도구들(Claude, ChatGPT, Cursor, Gemini, Copilot)이 우리...
Toss Frontend Fundamentals 모의고사 2회차 리팩토링 후기
2026. 3. 28. · 25 min read
이번 포스팅에서는 Toss Frontend Fundamentals 모의고사 2회차에 참여하며 진행한 리팩토링 경험에 대한 이야기를 해보려고 한다. 평소 코드 리뷰나 리팩토링에 관심이 있었던 필자는, 토스에서 공개한 Frontend Fundamentals 모의고사라는 흥미로운 형식의 과제를 진행하게되었다. 과제는 회의실 예약 앱이 주어지고, 이를 리팩토링하는...
queryKey
2026. 1. 4. · 41 min read
이번 포스팅에서는 TanStack Query의 queryKey에 대한 이야기를 해보려고 한다. 필자는 실무에서 TanStack Query를 쓰면서 queryKey 관리 방식을 몇 번이나 갈아엎었던 경험이 있다. 처음에는 그냥 컴포넌트 안에서 ['user', userId] 같은 배열을 인라인으로 박아 썼다가, 무효화할 때마다 같은 키를 여러 곳에 적느라 오타...