AI 에이전트 도구
이번 포스팅에서는 AI 코딩 에이전트를 둘러싼 도구 생태계에 대한 이야기를 해보려고 한다.
필자는 프론트엔드 개발자로 일하면서 일상적으로 Claude를 활용한다. 그러다 보니 어느 순간부터 프로젝트 루트에 CLAUDE.md가 생기고, 옆에 누가 만들어둔 AGENTS.md가 있고, .cursorrules도 한쪽에 남아있고, 어디선가 본 글을 따라 .claude/skills/ 폴더를 만들기도 했다. (정신을 차려보니 비슷한 내용을 적어둔 파일이 다섯 개쯤 되어 있었다.)
비슷한 혼란이 다른 영역에서도 생겼다. serena라는 MCP를 추가해보고, codegraph라는 게 GitHub Trending에 오른 걸 보고 따라 설치해보고, 또 이런저런 새 도구들을 발견할 때마다 "이게 도대체 어디에 속하는 도구이고 어떻게 작동하는 거지"라는 의문이 반복됐다. (특히 누가 만든 도구인지, 어떤 원리로 토큰을 아끼는 건지 같은 부분에서 매번 가물가물했다.)
그래서 필자는 이번 글에서 도구를 하나씩 추천하기보다는, 도구의 지형도 자체를 그려보기로 했다. 아래 네 가지 큰 축으로 나눠보았다.
- 컨텍스트 파일(
.md)들의 차이 - MCP의 원리와 Serena
- 코드 인텔리전스 도구의 계층 구조와 CodeGraph
- GitHub Trending에 관심 가져보기
이 네 가지를 알고 나면 새로운 도구가 등장했을 때 "아 이건 이 이런 느낌이구나" 하고 가늠할 수 있을 것이라고 본다.
컨텍스트 파일
AI 코딩 에이전트에는 지속 메모리가 없다는 근본적인 한계가 있다. 모든 세션은 빈 상태로 시작되고, 어제 합의한 컨벤션이나 한 시간 전에 알려준 폴더 구조 같은 것을 다음 대화에서는 기억하지 못한다. 컨텍스트 파일은 이 문제를 해결하기 위한 가장 단순한 장치다. 세션이 시작될 때마다 자동으로 읽히는 파일을 프로젝트에 두면, 매번 같은 설명을 반복할 필요가 없다.
문제는 같은 발상에서 출발한 파일이 도구마다 따로 만들어졌다는 점이다. Claude Code는 CLAUDE.md를, Cursor는 .cursorrules(현재는 depreacted가 되어 .cursor/rules 사용을 권장하고있다)를, GitHub Copilot은 .github/copilot-instructions.md를, OpenAI Codex는 AGENTS.md를 읽는다. 한 팀이 여러 도구를 쓰면 같은 내용을 네 군데에 복사해 두어야 하는 상황이 벌어지는 것이다.
CLAUDE.md
CLAUDE.md는 Claude Code가 세션 시작 시 자동으로 읽어 들이는 파일이다. Anthropic 공식 문서(code.claude.com/docs/en/memory)에 따르면, Claude Code는 다음 세 계층에서 CLAUDE.md를 찾는다.
- 사용자 메모리 (
~/.claude/CLAUDE.md): 머신의 모든 프로젝트에 적용되는 전역 기본값 - 프로젝트 메모리 (프로젝트 루트의
CLAUDE.md): 깃에 커밋되어 팀 전체가 공유 - 로컬 메모리 (서브디렉토리의
CLAUDE.md): 해당 디렉토리에서 작업할 때만 추가로 로딩
세 계층이 모두 존재하면 Claude는 모두 읽어 연결(concatenate) 한다. 우선순위에 따라 하나만 선택되는 게 아니라, CSS의 cascade처럼 더 구체적인 것이 추가로 얹히는 구조다. (오버라이드가 아니라 병합이다.) 따라서 같은 주제의 규칙을 여러 계층에 흩어두면 충돌이 날 수 있다.(Anthropic 공식 문서는 충돌 시 동작이 보장되지 않는다고 명시하고있다.)
여기서 한 가지 자주 놓치는 부분이 있다. 현재 작업 디렉토리에서 레포 루트까지 거슬러 올라가며 만나는 모든 CLAUDE.md를 읽는다는 점이다. 그래서 모노레포에서 packages/ui/에 들어가서 작업하면 루트의 CLAUDE.md와 packages/ui/CLAUDE.md가 둘 다 로딩된다. (이건 강력하지만 동시에 컨텍스트가 부지불식간에 부풀 수 있다는 뜻이기도 하다.)
AGENTS.md
AGENTS.md는 위에서 말한 도구별 파일 난립을 풀기 위해 만들어진 표준이다. 2025년 12월, Anthropic·Block·OpenAI 세 회사가 MCP와 함께 Linux Foundation 산하 Agentic AI Foundation(AAIF) 에 기증하면서 사실상의 업계 표준이 되었다. 공식 사이트(agents.md)에서 6만 개 이상의 오픈소스 저장소가 이 파일을 채택하고 있다고 명시하고 있다.
지원하는 도구 목록을 보면 더 분명해진다. OpenAI Codex, Google Jules, VS Code, GitHub Copilot, Cursor, JetBrains Junie, Aider, Devin, Zed, Factory, Warp, goose, opencode, Amp, RooCode, Gemini CLI, Kilo Code, Phoenix, Semgrep, Ona, Windsurf, Augment Code 까지 수많은 도구들을 지원한다. GitHub Copilot은 2025년 8월부터 AGENTS.md를 네이티브로 지원하기 시작했다. 한 가지 흥미로운 점은 Claude Code의 네이티브 AGENTS.md 지원은 아직 active feature request 상태라는 것이다. Claude Code는 여전히 CLAUDE.md를 1차 파일로 본다.
표준이라고는 하지만 정말 채택되고 있는지 의심스러울 수도 있다. 가장 강력한 증거는 dogfooding(자신이 만든 표준을 자신이 직접 쓴다는 의미)이다.
- Vercel/Next.js의 canary 브랜치 루트에는
AGENTS.md가 있다. 사실은CLAUDE.md를 가리키는 심볼릭 링크인데, 그 안에 모노레포 구조,pnpm --filter=next dev로 1-2초 단위 반복, Turbopack/Webpack 양쪽 테스트 가이드,pr-status스크립트, 환경 변수·시크릿 처리 규칙까지 들어 있다.create-next-app이 신규 프로젝트에AGENTS.md와CLAUDE.md를 함께 생성하도록 바뀐 것도 같은 흐름이다. - OpenAI/codex 레포 자체가 자신의
AGENTS.md를 운영한다.
전략적으로는 이렇게 운용하는 게 정석으로 굳어지고 있다. AGENTS.md를 단일 정보 출처(single source of truth)로 두고, CLAUDE.md는 최소화해서 AGENTS.md를 참조하는 한 줄과 Claude Code 전용 지시만 적어두는 방식이다. 이렇게 하면 중복이 사라지고, Claude Code는 두 파일을 모두 읽기 때문에 잃는 것이 없다.
SKILL.md
SKILL.md는 위 두 파일과는 결이 다르다. CLAUDE.md와 AGENTS.md가 항상 컨텍스트에 존재하는 영속적 지시라면, 스킬(Skill)은 필요할 때만 호출되는 온디맨드 능력이다.
스킬은 폴더 단위로 구성된다. 폴더 안에 SKILL.md 한 개와 그 스킬이 실행할 스크립트, 추가 마크다운 문서들이 들어있다. Claude는 현재 태스크가 스킬의 description과 매칭될 때만 그 폴더를 로딩한다. 이걸 progressive disclosure(점진적 노출) 라고 부르는데, 1995년 UX 분야의 Jakob Nielsen이 정립한 개념으로 고급·드물게 쓰이는 기능을 보조 화면으로 미뤄두고 사용자가 한 번에 하나의 작업에만 집중하게 해서 인지 부하와 에러를 줄이는 기법이다. Claude Skills 맥락에서는 "필요할 때만 그 스킬의 본문을 컨텍스트로 가져오는" 메커니즘을 가리킨다. 결과적으로 컨텍스트 윈도우 비용을 극적으로 아낄 수 있다.
SKILL.md의 frontmatter에는 몇 가지 고유한 필드가 있다.
description: 어떤 상황에서 이 스킬이 필요한지 설명. 모델이 호출 여부를 판단하는 트리거가 된다allowed-tools: 스킬 안에서 사용 가능한 도구를 제한 (예:"Read, Glob, Grep, Bash(python:*)")disable-model-invocation: true: 모델은 호출 불가, 사용자만 슬래시 명령으로 트리거 가능하다. 부작용 있는 작업(배포·커밋 등)에 사용한다user-invocable: false: 사용자에게는 슬래시 메뉴에서 안 보이고 Claude만 자율 호출하여 배경 지식용에 사용한다.
Claude Skills는 2025년 10월 16일 Claude.ai, Claude Code, API, Agent SDK에 동시 출시되었다. 그리고 2025년 12월 18일, Anthropic은 Skills 사양 자체를 오픈 표준(agentskills.io)으로 발표했다. Simon Willison은 "Skills are awesome, maybe a bigger deal than MCP"라는 평가를 내놓기도 했는데, 그 이유는 형식이 MCP보다 극적으로 단순하면서 컨텍스트 윈도우 비용 문제를 progressive disclosure로 해결한다는 점에 있었다.
다른 도구들의 파일
Cursor의 .cursorrules는 0.43 버전부터 deprecated 되었다. 현재 공식 권장은 .cursor/rules/ 디렉토리 안에 여러 .mdc 파일을 두는 것이다. 각 .mdc 파일은 YAML frontmatter를 가진다.
description: 에이전트가 이 룰의 관련성을 판단할 때 참고globs: 매칭되는 파일이 대화에 포함될 때 자동 첨부(auto-attach)alwaysApply:true면 모든 대화에 무조건 포함 (이 경우globs는 무시)
GitHub Copilot도 비슷한 방향으로 진화했다. 저장소 전역 지시는 .github/copilot-instructions.md에 두고, 경로별 스코프가 필요한 지시는 .github/instructions/*.instructions.md 파일을 만들어 frontmatter의 applyTo: 키로 glob을 지정한다. (Copilot code review는 2025년 9월부터 path-scoped instructions를 공식 지원한다.)
Cursor·Copilot 외의 도구들도 모두 비슷한 패턴으로 수렴하고 있다. 표로 정리하면 이렇다.
| 도구 | 파일/디렉토리 | 특징 |
|---|---|---|
| Claude Code | CLAUDE.md (3계층) |
디렉토리 트리 따라 병합 |
| Cursor | .cursor/rules/*.mdc |
globs로 파일 패턴 스코핑 |
| GitHub Copilot | .github/copilot-instructions.md + .github/instructions/*.instructions.md |
applyTo glob 지원 |
| Cline | .clinerules/ 디렉토리 |
모든 .md/.txt 통합, paths glob 조건부 활성화 |
| Continue.dev | .continue/rules/*.md |
name/globs/alwaysApply frontmatter |
| Aider | CONVENTIONS.md + .aider.conf.yml |
매 요청마다 포함, 200줄 이내 권장 |
| Windsurf | .windsurfrules + global_rules.md |
글로벌과 프로젝트 2단계 |
| 표준 | AGENTS.md (AAIF) |
60,000+ 저장소 채택 |
특히 Aider의 CONVENTIONS.md가 흥미롭다. 공식 문서는 매 요청마다 이 파일을 통째로 컨텍스트에 포함하기 때문에 "200줄 이내로 유지하라" 고 명시한다. (Aider는 이 한계를 일찍 인지하고 사용자에게 명시적으로 알려주는 셈이다.)
MEMORY.md
위 파일들과는 별개로, 점점 자주 보이는 패턴이 하나 더 있다. MEMORY.md다. 공식 표준은 아니지만 커뮤니티에서 자생적으로 생겨난 컨벤션인데, 시간이 흐르는 동안의 의사결정과 실수를 기록하는 용도다.
## 2026-04-10
Pages Router에서 App Router로 이전. 신규 라우트는 App Router 컨벤션 사용.
## 2026-04-22
Prisma 쿼리 결과에 optional chaining 쓰지 말 것 — null은 if-check로 명시적 처리.
(이전에 옵셔널 체이닝으로 null을 흘려보내 프로덕션 이슈 발생.)CLAUDE.md나 AGENTS.md가 현재 시점의 규칙을 적는 곳이라면, MEMORY.md는 그 규칙이 왜 만들어졌는지의 역사를 적는 곳이다. (둘은 보완 관계지 대체 관계가 아니다.)
에이전트는 이 파일들을 어떻게 읽는가
지금까지 어떤 파일이 있는지를 정리했다. 그런데 의외로 자주 빠지는 질문이 하나 있다. 이 파일들을 에이전트는 정확히 어디로, 어떻게 읽어들이는 걸까? 사실 이 메커니즘을 알면 뒤에 이어질 ETH Zurich 결과(컨텍스트 파일이 잘 안 따라진다는 결과)가 왜 나왔는지가 좀 더 깔끔하게 이해된다.
가장 먼저 짚어둘 사실 하나. CLAUDE.md는 system prompt가 아니라 user message로 주입된다. Anthropic 공식 문서가 아래와 같이 명시한다
CLAUDE.md content is delivered as a user message after the system prompt, not as part of the system prompt itself. Claude reads it and tries to follow it, but there's no guarantee of strict compliance.
즉 강제 규칙이 아니라 "참고용 컨텍스트"인 셈이다. 정확히 어떤 동작을 강제하고 싶다면 PreToolUse 훅 같은 별도 장치를 써야 한다고 공식 가이드도 권장한다.
로드 순서는 broad → specific 으로 쌓인다. 구체적으로는 managed policy(조직 차원의 설정) → 사용자 글로벌(~/.claude/CLAUDE.md) → 프로젝트(./CLAUDE.md) → 로컬(./CLAUDE.local.md) 순이다. 같은 디렉토리에서는 CLAUDE.md 다음 CLAUDE.local.md 순. 가장 가까운 곳의 지시가 가장 나중에 읽힌다는 점을 활용하면 (LLM의 recency bias 덕에) 더 구체적인 규칙이 더 강하게 작용하는 효과를 노릴 수 있다.
여기서 흥미로운 게 @import 문법이다. CLAUDE.md 본문 어디에 @path/to/file을 적으면 그 파일이 자리에 그대로 펼쳐져서 같이 로드된다. 최대 재귀 깊이는 4 hops까지 허용되고, 상대경로는 import문이 적힌 파일 기준으로 풀린다. 그래서 공식 권장이 @AGENTS.md로 브리지하는 방식이다. CLAUDE.md는 거의 비워두고 @AGENTS.md 한 줄만 쓰면 Claude Code도 자연스럽게 AGENTS.md를 읽는다. (CLAUDE.md가 아직 AGENTS.md를 네이티브 지원하지 않는 현 상황에서 가장 깔끔한 우회다.)
토큰 측면도 짚고 가자. CLAUDE.md 자체에는 명시적 토큰 한도가 없어서 있으면 전부 로드된다. 다만 공식 권고는 파일당 200줄 이내다. 200줄을 넘기면 "consume more context and may reduce adherence"라고 명시되어 있다. 흥미롭게도 Claude 4.x에서는 tool use를 활성화하는 것만으로 special system prompt가 자동 +346토큰(tool_choice: auto 기준) 추가된다. 컨텍스트는 알게 모르게 새고 있는 셈이다.
Cursor는 또 다른 방식이다. .cursor/rules/*.mdc의 룰은 네 가지 타입으로 작동한다.
- Always Apply: 모든 채팅에 무조건 포함. globs/description 무시
- Apply Intelligently(Agent Requested): 에이전트가
description을 읽고 관련성을 판단해 끌어다 씀 - Apply to Specific Files(Auto Attached): glob 패턴 매칭 파일이 컨텍스트에 들어왔을 때 활성화
- Apply Manually:
@rule-name으로 사용자가 명시 호출
다른 도구들은 또 다르다. OpenAI Codex는 git 레포 루트에서 cwd 방향으로 walk하며 모든 AGENTS.md를 수집해 사용자 프롬프트 직전에 주입하고, GitHub Copilot은 .github/copilot-instructions.md를 "edit context와 explicit references 다음, loosely related open files보다는 앞"이라는 컨텍스트 윈도우의 중간 우선순위로 끼워 넣는다. 같은 AGENTS.md 파일이라도 로드 시점, 우선순위, 머지 규칙이 도구마다 다르기 때문에 세 도구가 정확히 같은 방식으로 그 파일을 본다는 보장은 없다.
그런데 여기서 한 가지 근본적인 질문이 남는다. 왜 모델은 컨텍스트에 있는 지시를 일부만 따르는 걸까? 단순히 "지시가 길어서"라는 설명은 충분하지 않다. 이 현상의 밑에는 LLM의 구조적 한계가 있다.
환각과 컨텍스트 망각
AI 에이전트가 대화 맥락을 혼동하거나 앞에서 분명히 말한 내용을 뒤에서 잊어버리는 경험을 해본 적이 있다면, 그게 바로 환각(Hallucination) 의 한 형태다. 일반적으로 환각이라고 하면 "없는 사실을 지어내는 것"을 먼저 떠올리지만, 학술적으로는 세 가지로 구분한다. Yue Zhang 외 연구팀의 2023년 설문("Siren's Song in the AI Ocean")은 이를 입력 충돌형(사용자가 명시한 내용과 다르게 생성), 맥락 충돌형(이전에 자신이 생성한 내용과 모순), 사실 충돌형(세계 지식과 불일치)으로 나눈다. 컨텍스트 파일 지시를 무시하는 현상은 세 번째가 아니라 첫 번째 유형이다. 모델이 입력을 처리하면서 그 안의 정보 일부를 "없던 것처럼" 다루는 것이다.
더 근본적인 문제는 이 환각이 원천적으로 제거 불가능하다는 점이다. 싱가포르 국립대학교 연구팀은 학습 이론을 이용해 이를 수학적으로 증명했다. 어떤 LLM도 모든 계산 가능한 함수를 학습할 수 없고, 따라서 일반 문제 해결기로 쓰이는 한 반드시 어느 지점에서 환각이 발생한다는 것이다.
위치 효과도 중요하다. Stanford 연구팀은 관련 정보가 컨텍스트 윈도우의 앞이나 끝에 위치할 때 모델이 가장 잘 참조하고, 중간에 묻혔을 때 성능이 크게 떨어진다는 것을 실험으로 보였다. 이게 컨텍스트 파일에 직접 연결된다. CLAUDE.md가 로드 순서상 중간 어딘가에 끼어 들어가고, 그 뒤로 대화가 길어질수록 파일의 지시는 점점 컨텍스트의 "중간"으로 밀려난다. 앞서 언급한 recency bias(최근 것을 더 잘 따르는 경향)의 반대편, 즉 primacy-recency 효과의 중간 구간이 가장 취약하다는 사실과도 맞닿아 있다.
결국 이 현상들을 한데 놓으면 하나의 그림이 된다. 컨텍스트 파일은 LLM의 첫 user 턴 이전에 시스템 외부에서 추가로 끼어 들어가는 텍스트일 뿐이다. 모델의 결정을 강제하는 메커니즘이 아니라 그저 컨텍스트 윈도우에 떨어지는 또 하나의 토큰 덩어리인 것이다. 길수록, 그리고 대화가 길어질수록 그 지시는 점점 "중간"으로 밀려나며 참조율이 떨어진다. ETH Zurich 결과는 이 구조적 한계를 정량적으로 확인한 셈이다.
ETH Zurich의 연구
많은 사람들은 "그럼 이 파일들에 최대한 많이 적어두면 좋겠네?" 하는 생각을 했을 것이다. 그런데 이 직관을 정면으로 반박하는 연구가 최근에 나왔다. 바로 앞에서 계속 이야기한 ETH Zurich 연구이다.
ETH Zurich 연구팀이 2026년 2월에 발표한 논문("Evaluating AGENTS.md: Are Repository-Level Context Files Helpful for Coding Agents?")이다. 138개의 실제 Python 소프트웨어 엔지니어링 태스크 벤치마크(AGENTBENCH)와 SWE-bench Lite에서 Claude Code(Sonnet-4.5), Codex(GPT-5.2 / GPT-5.1 mini), Qwen Code 네 가지 에이전트로 측정했는데, 결과가 의외였다.
- LLM이 자동 생성한 컨텍스트 파일은 SWE-bench Lite에서 0.5%, AGENTBENCH에서 2% 가량 태스크 성공률을 오히려 낮췄다
- 사람이 직접 작성한 파일조차 평균 4% 정도의 마이너 개선에 그쳤다
- 컨텍스트 파일을 추가했을 때 추론 비용이 인스턴스당 20% 이상 증가했다
- 더 강력한 모델(GPT-5.2)에서는 컨텍스트 파일의 효과가 더 미미했다 (강력한 모델일수록 파라메트릭 지식이 충분해서 추가 컨텍스트가 노이즈로 작용)
다만 한 가지 예외가 있었다. 비표준 도구를 명시했을 때다. 예를 들어 Python 패키지 매니저인 uv를 컨텍스트에 명시하니, 에이전트가 uv를 사용하는 빈도가 인스턴스당 0.01회 => 1.6회로 약 160배 증가했다
앞서 다룬 Aider의 "200줄 권고", "매번 컨텍스트에 들어가니까 짧게 유지하라"라는 실용성을 안내한 거고, ETH Zurich 연구는 "긴 컨텍스트 파일이 통계적으로 성능을 떨어뜨린다"는 걸 정량적으로 보여줬다. 필자가 생각하는 이 연구의 실천적 함의는 아래와같다.
- 자동 생성된 거대한 컨텍스트 파일은 도움보다 해가 될 수 있다. 300줄짜리
CLAUDE.md에 코딩 표준·아키텍처·워크플로우를 다 욱여넣으면, 에이전트는 일부만 따르고 나머지를 무시한다. 그 불일관성은 차라리 컨텍스트가 없는 것보다 나쁜 결과로 이어진다. - 반드시 적어야 하는 것은 "추론할 수 없는 정보" 다. 비표준 도구, 프로젝트 고유의 컨벤션, 과거 실패 사례 같은 것들이 여기에 속한다. 일반적인 코딩 베스트 프랙티스는 모델이 이미 안다.
- AGENTS.md를 단일 출처로, CLAUDE.md는 도구 전용 짧은 지시만, 세한 워크플로우는 Skill로 분리한다.
MCP(Model Context Protocol)
.md 파일들이 "에이전트에게 무엇을 알려줄까"의 문제를 풀었다면, MCP(Model Context Protocol)는 "에이전트에게 무엇을 할 수 있게 해줄까"의 문제를 푼다.
조금 풀어쓰면 이렇다. AI 에이전트가 Slack에 메시지를 보내려면 Slack API를 호출할 수 있어야 한다. GitHub 이슈를 만들려면 GitHub API를 호출할 수 있어야 한다. Postgres에 쿼리하려면 DB 연결을 다룰 수 있어야 한다. 이 모든 외부 시스템과의 통합을 하나의 표준 프로토콜로 묶은 것이 MCP다. (어떤 클라이언트든 어떤 서버든 같은 포트로 연결된다는 의미다)
MCP는 Anthropic이 2024년 11월 25일에 처음 공개한 개방형 표준이다. 그리고 2025년 12월 9일, Anthropic·Block·OpenAI 세 회사가 공동 창립자로 Linux Foundation 산하 Agentic AI Foundation(AAIF) 에 MCP 사양을 기증했다. Google·Microsoft·AWS·Cloudflare·Bloomberg가 플래티넘 멤버로 합류했다. (2025년 12월 기증 시점에 이미 월 9,700만 회 이상의 SDK 다운로드와 1만 개 이상의 활성 공개 MCP 서버가 있었다.)
MCP는 이 JSON-RPC 위에 만들어진 상태 유지(stateful) 세션 프로토콜이다. JSON-RPC은 JSON을 와이어 포맷으로 쓰는 stateless·경량 RPC(Remote Procedure Call) 프로토콜이다. 전송 계층에 독립적이어서 HTTP·TCP·표준 입출력 무엇이든 위에서 동작한다. notification(응답이 없는 호출)과 batch 호출도 지원한다.
프로토콜 내부
MCP에서 클라이언트와 서버가 주고받는 모든 상호작용은 여섯 가지 원시타입(primitive) 중 하나로 표현된다. 처음엔 서버측 3개로 출발했지만, 2025-06-18 spec에서 클라이언트측 원시타입 3개가 보강되어 지금은 총 6개가 표준이다.
서버측 원시타입
- Tool (model-controlled): 모델이 호출 여부를 스스로 판단해 실행하는 동작이다. 이런 동작은 부작용(side effect)을 가질 수 있다
- Resource (application-controlled): URI로 식별되는 읽기 전용 데이터들을 의미한다. 어떤 리소스를 노출할지는 호스트 애플리케이션이 결정한다.
- Prompt (user-controlled): 사용자가 슬래시 명령 등으로 명시적으로 트리거하는 재사용 가능한 템플릿이다.
클라이언트측 원시타입
- Sampling: 서버가 거꾸로 클라이언트의 LLM에게 completion을 요청할 수 있게 해주는 메커니즘으로 클라이언트와 서버를 양방향 구조로 만든다.
- Roots: 클라이언트가 서버에게 "여기까지가 작업 가능한 범위"라고 알려주는 워크스페이스 경계 정보
- Elicitation: 서버가 도구를 실행하는 도중에 사용자에게 추가 입력을 구조화된 형태로 요청할 수 있게 해주는 기능
이 6가지의 구분이 중요한 이유는, 누가 호출/제공을 결정하는가의 권한이 다르기 때문이다. Tool은 모델의 자율 판단으로 실행되니 잘못된 호출의 리스크가 있다. Resource는 앱이 큐레이션하니 비교적 안전하다. Prompt는 사용자가 명시적으로 트리거하니 가장 통제 가능하다. Sampling/Roots/Elicitation은 클라이언트 측 제어로 권한 모델을 더 정교하게 만든다.
전송 방식은 딱 두 가지다. 이는 의도된 설계인데, 생태계가 수십 개의 경쟁 프로토콜로 분열되지 않도록 하기 위함이다. 하나는 stdio로, MCP 서버를 로컬 서브프로세스로 실행하고 표준 입출력으로 통신하는 방식이다. 파일시스템이나 깃처럼 로컬에서 동작하는 도구에 적합하다. 다른 하나는 Streamable HTTP인데, HTTP POST 위에 SSE 스트리밍을 얹어서 양방향에 가까운 통신을 만들어내는 방식이다. 원격 서버, OAuth 인증, 다중 클라이언트 연결, 클라우드 배포처럼 네트워크 너머에서 일어나는 시나리오에 적합하다.
여기서 SSE(Server-Sent Events)는 HTTP 연결을 통해 서버가 클라이언트로 단방향 데이터를 푸시하는 W3C 표준이다. media type은 text/event-stream이고 자바스크립트에서는 EventSource API로 접근한다. WebSocket과 달리 단방향이지만 HTTP 위에서 동작하므로 프록시·방화벽 친화적이라는 장점이 있다. Streamable HTTP는 이 SSE를 활용해서 양방향 통신을 흉내내는 셈인데, 2025년 3월 26일 spec(version 2025-03-26)에서 도입되어 기존의 HTTP+SSE 전송을 대체했다.
LLM이 MCP 도구를 호출하는 흐름
원시타입과 전송 방식까지 봤으니, 이제 실제로 LLM이 MCP 도구를 어떻게 발견하고 호출하는지의 흐름을 따라가보자. (.md 파일이 "어디로 주입되는가"의 문제였다면, 여기서는 MCP가 "어떻게 LLM의 시야에 들어오는가"의 문제다.)
MCP 세션이 시작되면 다음 순서의 핸드셰이크가 일어난다.
- 클라이언트 → 서버:
initialize요청 (지원하는 프로토콜 버전, 클라이언트 capabilities 전달) - 서버 → 클라이언트:
initialize응답 (서버 capabilities + 선택적으로instructions필드) - 클라이언트 → 서버:
notifications/initialized알림 - 클라이언트 → 서버:
tools/list요청 → 사용 가능한 도구 목록 수신 - (이후) LLM이 도구를 호출하기로 결정 → 클라이언트가
tools/call발송 → 결과 수신
여기서 한 가지 자주 간과되는 게 있다. initialize 응답의 instructions 필드다. 서버가 이 필드에 텍스트를 담아 보내면, 그 내용은 사실상 LLM의 시스템 프롬프트에 추가된다. 즉 MCP 서버가 "이 도구들을 어떤 식으로 써야 하는지"에 대한 가이드를 LLM에게 직접 주입할 수 있는 정식 슬롯이 spec에 존재한다는 뜻이다. (앞에서 다룬 Tool Poisoning Attack이 위험한 이유 중 하나가 바로 이 슬롯의 존재다.)
그러면 tool 정의 자체는 어떻게 LLM의 시야에 들어갈까. MCP의 tool 정의는 다음과 같은 JSON Schema 형태다.
{
"name": "get_weather",
"description": "Get current weather information for a location",
"inputSchema": {
"type": "object",
"properties": { "location": { "type": "string" } },
"required": ["location"]
}
}클라이언트가 tools/list로 받은 이 목록을 Anthropic Messages API의 tools 파라미터 또는 OpenAI function calling의 tools 파라미터로 변환해서 LLM API 호출에 같이 넣는다. Anthropic의 경우, tool 파라미터가 들어오면 special system prompt가 자동으로 추가되어 모델이 tool 호출 방식을 이해하도록 만든다. (이게 앞에서 언급한 +346토큰의 정체다.)
LLM이 도구를 호출해야 한다고 판단하면 응답 안에 tool_use 블록({"type": "tool_use", "name": ..., "input": ...})이 끼어 있고, 응답의 stop_reason이 tool_use로 끝난다. 클라이언트는 이걸 받아 실제 MCP 서버로 tools/call을 발송하고, 결과를 받아서 다음 user 메시지의 tool_result 블록에 담아 다시 LLM에 보낸다. stop_reason이 tool_use가 아닌 값(end_turn, max_tokens 등)으로 바뀔 때까지 이 루프가 반복된다. 우리가 흔히 "에이전트가 일한다"고 부르는 동작은 사실 이 호출-결과-호출 루프의 연속에 가깝다.
그렇다면 MCP는 단순 function calling과 뭐가 다른가? 네 가지 차이로 압축할 수 있다.
- 동적 발견: 빌드 타임에 도구 목록을 모르고 런타임에
tools/list로 가져온다.notifications/tools/list_changed로 세션 도중 변경도 가능 - Stateful session: lifecycle phase가 정의돼 있어서(initialize → operation → shutdown) 깔끔한 종료가 가능
- Tool 외 원시타입: Prompt·Resource·Sampling·Roots·Elicitation까지 capability negotiation으로 노출
- 양방향성: 서버가 거꾸로 클라이언트의 LLM을 sampling으로 호출하는 것도 spec상 가능
(이 차이 때문에 MCP를 "에이전트용 function calling의 일반화된 표준"이라고 부르기도 한다.)
Serena
Serena(oraios/serena)는 MCP 서버 중에서도 코딩 에이전트와 관련해 가장 자주 언급되는 도구다. 2026년 5월 현재 약 24.7k stars로, 약 1년 만에 비주류 도구에서 사실상의 표준 코드 MCP로 올라섰다.
Serena의 핵심 아이디어는 한 줄로 요약된다. 에이전트에게 텍스트가 아니라 심볼을 보여주자.
조금 풀어쓰자면 이런 이야기다. calculateTotal 함수의 모든 사용처를 찾아야 한다고 해보자. 일반적인 텍스트 기반 도구(grep, Read 같은 것)는 이렇게 동작한다.
전체 코드베이스를 calculateTotal로 grep 한다. 이후 매치된 모든 라인의 라인 번호를 수집하고, 각 파일을 일정 라인 범위 만큼 읽어서 컨텍스트를 만든다. 변수명·문자열 리터럴·주석에 우연히 들어간 매치까지 다 잡힌다.
LSP 기반의 Serena는 find_referencing_symbols("calculateTotal") 를 단일 호출하여 변수명 매치, 주석 매치 같은 잡음 없이 정확한 심볼 참조만 반환한다.
LSP (Language Server Protocol)는 코드 에디터/IDE와 "언어 인텔리전스 도구"(코드 완성, 정의로 이동, 참조 찾기, 리팩토링 등) 사이의 통신을 표준화한 JSON-RPC 기반 개방형 프로토콜이다. 2016년 Microsoft·Red Hat·Codenvy가 공동 표준화했다. 핵심 아이디어는 "에디터마다 언어 분석기를 재구현하지 말고, 언어별 서버 하나를 두고 모든 에디터가 그 서버에 질의하자"는 것이다. (TypeScript 서버, Rust analyzer, Python의 pyright 등이 모두 LSP 서버다.)
Serena의 핵심 도구는 find_symbol, find_referencing_symbols, get_symbols_overview 등이다. 백엔드는 두 가지 중 하나를 선택할 수 있다. 기본값은 LSP를 구현한 언어 서버(무료/오픈소스), 다른 옵션은 JetBrains IDE의 코드 분석을 활용하는 유료 플러그인(무료 체험 제공)이다.
Serena가 빠르게 채택된 진짜 이유는 토큰 절약이다. 텍스트 grep + 파일 read 루프는 토큰을 많이 잡아먹지만, LSP 한 번의 정확한 호출은 거의 안 든다. 큰 코드베이스일수록 차이가 커진다.
그래서 MCP는 안전한가?
여기서 한 가지 짚고 가야 할 게 있다. MCP는 권한 부여를 자동화하지 않는다. 에이전트가 어떤 서버를 신뢰할 수 있는지, 어떤 도구가 어떤 부작용을 가지는지, 그 도구가 시간이 지나도 같은 동작을 할지는 모두 사용자가 책임져야 한다.
대표적인 공격 두 가지를 알아두면 좋다.
-
Tool Poisoning Attack(TPA) : Invariant Labs가 2025년 4월에 명명하고 PoC를 공개한 공격이다. MCP 서버의 도구 설명(description)에 악의적 지시사항을 숨겨두면, 모델은 그것을 사용자 지시로 착각하고 따른다. 사용자에게는 보이지 않는 텍스트지만 모델에는 보이는 것이다.
-
Rug Pull(Silent Redefinition): Simon Willison이 2025년 4월 9일 공개 분석에서 다룬 개념이다. 도구는 처음엔 합법적으로 시작된다. 사용자가 검토하고 승인하고 워크플로우에 통합한다. 몇 주 뒤, 도구 정의가 조용히 변경되어 악성 지시사항이 포함된다. 사용자는 재승인을 받지 않았으니 그대로 동작이 바뀐다.
보안 관련 사건이 2026년 4월 15일에 있었다. OX Security가 모든 주요 MCP SDK(Python·TypeScript·Java·Rust)에 영향을 미치는 시스템적 RCE 취약점들을 공개했다. 1억 5천만 회 이상의 다운로드, 약 7,000개의 공개 서버, 약 20만 개의 추정 취약 배포가 영향권에 들어갔다. 14개 이상의 CVE가 할당되었고, Cursor·VS Code·Windsurf·Claude Code·Gemini-CLI 등이 모두 영향을 받았다.
사후 대응은 어떻게 진행되고 있을까? Anthropic은 프로토콜 아키텍처 자체는 수정하지 않았다. 대신 SECURITY.md를 업데이트해 stdio 어댑터 사용 시 입력 sanitization 책임이 다운스트림 개발자에게 있음을 명시했다. spec 차원에서는 2025-06-18 개정에서 OAuth 2.1 + RFC 8707 Resource Indicators를 의무화해서 토큰 재사용 공격을 차단했고, 2025-11-25 개정에서는 incremental scope consent(필요한 최소 권한만 단계적으로 사용자가 동의)를 도입했다. 그럼에도 2026년 1-2월에만 MCP 관련 CVE가 30건 넘게 발행됐고, 그중 command injection이 43% 를 차지한다는 통계가 나왔다. 보안 영역은 여전히 진행형인 셈이다.
코드 인텔리전스 도구
.md 파일이 "무엇을 알려줄까"이고 MCP가 "무엇을 할 수 있게 해줄까"라면, 코드 인텔리전스 도구는 "관련 코드를 어떻게 빨리 찾을까"의 문제를 푼다.
대형 코드베이스에서 AI 에이전트의 비용 대부분은 코드 변경 자체가 아니라, 관련 코드가 어디 있는지 찾는 데 소모된다. 모든 태스크가 grep → read → 필터 → 다시 grep의 반복으로 시작되면 토큰·시간·툴 콜이 낭비된다. 코드 인텔리전스 도구는 이 검색 비용을 줄이기 위한 다양한 시도들이다.
이걸 네 개의 계층(tier)으로 나눠서 보면 머릿속이 정리된다.
컨텍스트 패킹
가장 단순한 해법은 "전부 다 한 컨텍스트 윈도우에 넣어버리자"는 발상이다. 그래프도 안 만들고, 인덱싱도 안 한다. 그냥 레포 전체를 텍스트 덩어리로 직렬화해서 모델에게 통째로 던진다.
대표 도구가 Repomix가 있다. 전체 레포를 Claude의 XML 파싱에 최적화된 구조로 패킹한다. CLI·웹·익스텐션·MCP 서버를 다 갖춰서 가장 완전한 생태계를 가진다.
GitIngest는 마찰 제로 사용성으로 유명하다. GitHub URL에서 github.com을 gitingest.com으로 한 단어만 바꾸면, 해당 레포 전체가 한 텍스트 페이지로 변환된다. (예: github.com/facebook/react → gitingest.com/facebook/react.) 브라우저 주소창에서 단어 하나 바꾸는 게 전부라서 별도 설치도 필요 없다. 1회성 빠른 탐색에 특화되어 있다.
code2prompt(Mufeed VH 제작)는 Rust 기반 CLI로, 템플릿 시스템을 통한 커스터마이징에 강점이 있다.
흥미로운 변종으로 rtk(rtk-ai/rtk, 약 55k stars)도 짚어둘 만하다. 위 도구들이 "레포 전체를 한 번에 패킹"한다면, rtk는 CLI 명령의 출력 자체를 실시간으로 압축하는 도구다. Rust로 만든 단일 바이너리인데, Claude Code·Cursor·Copilot·Gemini CLI·Codex 등 13개 도구의 shell hook에 자동 등록되어 에이전트가 git status를 호출하면 내부적으로 rtk git status로 rewrite한다. (사용자가 워크플로를 바꿀 필요가 없는 게 핵심 차별점이다.) 100개 이상의 명령에 대해 smart filtering·grouping·truncation·deduplication 휴리스틱을 적용해서 출력 토큰을 60~90% 줄여준다. 공식 사이트의 한 줄이 이 카테고리를 잘 요약한다 — "70% of your bill is noise the LLM doesn't need." 위 도구들이 "들어가는 컨텍스트"의 양을 줄이는 쪽이라면, rtk는 "tool call 결과로 돌아오는 컨텍스트"의 양을 줄이는 쪽이다.
다만 이 계층의 한계는 명확하다. 대형 레포는 토큰 한도에 걸린다. 그리고 코드를 "텍스트 덩어리"로만 전달할 뿐, 심볼 간 관계나 구조적 이해는 없다.
tree-sitter 레포맵
다음 계층은 tree-sitter를 활용해 코드의 구조를 분석하되, 별도의 인덱스 서버를 띄우진 않는 방식이다.
AST (Abstract Syntax Tree, 추상 구문 트리)은 소스 코드의 구조를 트리로 표현한 자료구조이다. 컴파일러의 구문 분석 단계 결과물로, 공백·세미콜론·괄호 같은 표면적인 디테일은 제거하고 변수·연산자·함수 호출·제어 흐름 같은 의미 있는 요소만 노드로 남긴다. 코드 인텔리전스 도구의 모든 정밀한 분석은 결국 AST 위에서 일어난다.
tree-sitter은 오픈소스 파서 생성기이자 증분(incremental) 파싱 라이브러리이다. GitHub의 코드 네비게이션, Neovim, Zed, Helix 등이 채택했다. 핵심 차별점은 편집된 부분만 다시 파싱한다는 점이다. 에디터에서 한 줄을 고쳐도 파일 전체를 재파싱하지 않고 변경된 트리만 패치한다. 그래서 응답 속도가 빠르고, AI 에이전트가 코드를 빠르게 훑는 용도로도 적합하다.
앞서 다룬 Aider가 이 접근의 대표 사례다. tree-sitter로 소스 파일에서 함수·클래스·메서드 같은 심볼 정의를 추출하고, 파일을 노드로, 파일 간 의존성을 엣지로 하는 그래프를 만들고, 그래프에 PageRank 계열의 랭킹 알고리즘(페이지로 들어오는 링크의 수와 품질로 페이지 중요도를 매기는 알고리즘)을 적용해 토큰 예산에 맞게 핵심 정의와 시그니처만 추출한다. (기본 --map-tokens=1024로 1k 토큰의 레포맵을 만든다.)
AFT(cortexkit/aft)는 이 접근을 더 정밀하게 발전시켰다. AFT 공식 README에 적힌 표현을 그대로 옮기면 이렇다. "500줄 파일을 읽으면 약 375 토큰이 든다. 하지만 에이전트가 대부분 한 함수만 필요로 할 때, aft_zoom에 심볼 이름을 넘기면 그 함수와 약간의 컨텍스트만 반환한다. 약 40 토큰정도가 발생한다." 그리고 라인 번호 기반 편집은 대상 위의 코드가 움직이는 순간 깨지지만, AFT의 심볼 모드 편집은 함수를 이름으로 주소 지정하기 때문에 안정적이다.
같은 계층에서 보너스로 짚을 만한 도구가 하나 더 있다. ast-grep(ast-grep/ast-grep, 약 13.9k stars)이다. tree-sitter 기반 구조적 검색·rewriting CLI인데, 일반 grep과 결정적으로 다른 점은 텍스트가 아니라 CST(Concrete Syntax Tree) 패턴으로 매칭한다는 것이다. 예를 들어 console.log($A) 패턴을 검색하면, 텍스트가 어떻게 생겼든 같은 의미 구조를 가진 모든 호출을 정확히 잡는다. 별도의 ast-grep-mcp 서버도 있어서 AI 에이전트가 텍스트 grep 대신 구조적 검색을 쓰게 만들 수 있다.
Knowledge Graph
세 번째 계층은 한 발 더 나아간다. 사전에 코드베이스 전체를 파싱해서 지식 그래프를 만들어 디스크에 저장해두고, 에이전트는 저장해둔 그래프에 쿼리를 던지는 방식이다. 가장 화제가 되는 사례가 CodeGraph 라는 도구이다.
아키텍처는 의외로 단순하다. tree-sitter로 코드를 파싱한 뒤, 그렇게 추출한 심볼·엣지·파일 정보를 SQLite의 FTS5 풀텍스트 검색에 저장하고, 그 지식 그래프를 MCP를 통해 AI 에이전트에 노출하는 구조다. 한 가지 짚고 갈 점은 이 모든 추출이 LLM 요약이 아니라 AST 파싱에서 결정론적으로 일어난다는 점인데, 환각이 끼어들 여지가 없다는 뜻이기도 하다.
여기 등장하는 FTS5(SQLite Full-Text Search 5) 는 SQLite의 가상 테이블 형태로 제공되는 전문 검색 확장이다. SQLite 3.9.0(2015-10-14)부터 amalgamation에 포함됐고, CREATE VIRTUAL TABLE ... USING fts5(...) 로 테이블을 만들어 MATCH 연산자로 질의한다. Elasticsearch 같은 별도 검색 엔진을 띄우지 않고도 SQLite 한 파일로 풀텍스트 인덱스를 운영할 수 있다는 게 결정적인 장점이고, CodeGraph가 "100% 로컬 동작"을 광고할 수 있는 이유 중 하나가 바로 이것이다.
그리고 방금 언급한 결정론적(deterministic) 파싱은 백트래킹 없이 각 단계에서 유일한 선택만 허용하는 파싱 알고리즘을 뜻한다. LL(1)·LR 파서가 대표적이며 선형 시간에 동작하는데, CodeGraph 맥락에서는 "AST에서 추출한 심볼 관계가 LLM의 해석이 아니라 수학적으로 정확하다"는 의미가 된다. LLM이 코드를 요약해서 그래프를 만들면 환각 위험이 있지만, AST를 직접 파싱하면 수학적으로 정확한 심볼 관계를 얻을 수 있다는 점에서 이 원칙이 핵심으로 작용한다.
벤치마크도 인상적이다. Claude Opus 4.7을 헤드리스로 실행하면서 CodeGraph MCP를 활성화한 경우와 비활성화한 경우를 비교했는데, 공식 README의 평균 수치 기준으로 35% 저렴해지고 57% 적은 토큰을 쓰고 46% 빨라지며 툴 콜은 71% 감소했다. 그리고 이 이득은 코드베이스 크기에 비례해 커지는데, Tokio처럼 큰 레포에서는 비용 82% 감소, 토큰 86% 감소, 속도 71% 향상, 툴 콜 92% 감소까지 측정되었다. (CodeGraph 없이는 에이전트가 grep/find/Read를 광범위하게 팬아웃하는데, CodeGraph가 있으면 그 모든 걸 인덱스 쿼리 한 번으로 대체하는 셈이다.)
학술적 맥락도 깊다. GraphCoder(ASE 2024)는 control flow와 data/control dependence를 통합한 Code Context Graph를 만들었다. CodexGraph(NAACL 2025)는 LLM 에이전트가 그래프 데이터베이스 쿼리를 직접 작성·실행하도록 했다. Prometheus는 tree-sitter 기반 지식 그래프와 통합 메모리를 결합해 다국어 이슈 해결에 적용했다. 이 방향은 명백히 학계와 산업이 동시에 수렴하고 있는 패턴이다.
여기서 한 가지 흥미로운 변종을 짚고 가자. Cursor의 인덱싱은 위와는 다른 길을 택했다. AST 그래프가 아니라 벡터 임베딩 기반 의미 검색이다. 로컬에서 파일을 함수·클래스 단위로 청크 분할하고, Merkle tree 해시로 서버와 동기화하고, 임베딩만 Turbopuffer라는 벡터 DB에 저장한다. (원본 소스코드는 클라우드에 저장하지 않는 게 핵심 프라이버시 모델이다.) 쿼리할 때는 질문을 임베딩해서 nearest-neighbor 검색을 돌리고, 그 결과로 받은 파일 경로·라인 범위를 로컬에서 다시 읽어 LLM에 넣는다. "정확한 심볼"이 아니라 "의미적으로 관련된 코드" 를 찾는 방향이라, 정밀도는 낮지만 자연어 질의에 강하다. CodeGraph와 Cursor 인덱싱은 동일한 문제(검색 비용)를 다른 가정으로 풀고 있는 셈이다.
LSP
마지막 계층은 언어 서버에 직접 의존하는 방식이다. tree-sitter가 "심볼이 존재한다는 것"을 안다면, LSP는 "그 심볼이 무엇인지"를 안다.
차이를 구체적인 예로 보자. TypeScript의 LSP는 UserService가 IUserService 인터페이스를 구현한다는 것을 알고, 어떤 제네릭 타입 파라미터를 받는지, 어떤 오버로드가 있는지, 어떤 반환 타입을 가지는지를 안다. tree-sitter는 거기까진 못 간다.
앞서 MCP에서 다룬 Serena가 정확히 이 계층이다. Aider는 LSP를 안 쓰고 자체 파일 분석을 하기 때문에 함수·클래스 수준의 인식까지만 가능하다. 반면 OpenCode 같은 도구의 LSP 통합은 더 깊은 타입 인식을 제공하지만, 언어별로 좋은 LSP 서버에 의존한다는 한계가 있다.
GitHub Trending
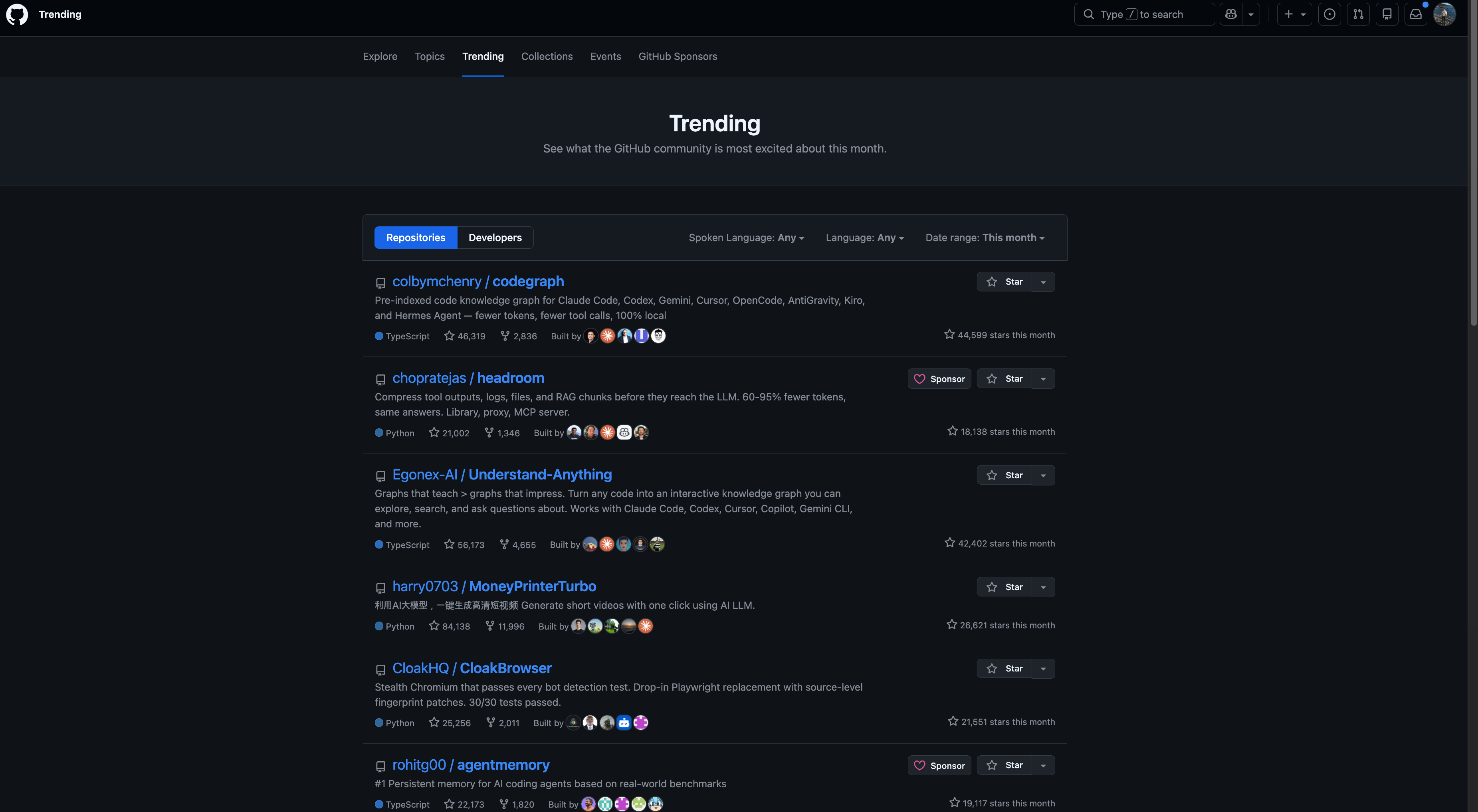
마지막으로 한 가지 더, 위 도구들 중 상당수를 필자가 처음 알게 된 통로가 GitHub Trending이다. 누가 어떤 도구를 만들었는지, 무엇이 갑자기 인기를 얻고 있는지를 한눈에 볼 수 있는 장소다.
github.com/trending에 들어가면 today, this week, this month 3가지 시간 단위로 볼 수 있다. 언어와 카테고리로도 필터링이 가능하다. (필자는 보통 weekly + TypeScript / Python으로 보고, 가끔 전체 언어로 확장한다.)
필자가 최근 몇 주간 Trending을 추적하면서 발견한 흥미로운 점은, 이번 분기의 상위 레포들이 명확한 클러스터를 형성한다는 사실이다. 클러스터를 알면 개별 도구를 더 잘 위치 지을 수 있다.
그래서
이 글을 쓰면서 필자가 가장 많이 한 생각은, 도구가 너무 빨리 늘어나고 있다는 것이었다. 글을 쓰는 동안에도 새로운 MCP 서버가 GitHub Trending에 올라왔고, AGENTS.md 지원 여부가 바뀌었고, 보안 CVE가 새로 발행됐다. 반쯤 완성된 문단이 금세 낡아버리는 느낌은 기술 글쓰기 특유의 숙명이지만, AI 에이전트 생태계는 그 속도가 유독 가파르다.
그래서 필자가 이 글에서 하려 했던 것은 특정 도구를 추천하는 것이 아니라, 도구들 사이의 관계를 보는 눈을 만드는 것이었다. CLAUDE.md가 왜 user message로 주입되는지, MCP가 function calling과 구체적으로 무엇이 다른지, tree-sitter와 LSP가 왜 서로 다른 계층인지를 알고 나면, 새로운 도구가 등장했을 때 "이건 어느 계층이고, 어떤 문제를 어떤 방식으로 푸는 거구나"가 빠르게 읽힌다.
결국 남는 건 ETH Zurich 연구가 건넨 한 가지 직관이다. 모델은 이미 많은 것을 안다. 컨텍스트 파일에 온갖 것을 욱여넣는다고 에이전트가 더 잘 따르지 않는다. 모델이 모를 가능성이 높은 것, 즉 프로젝트 고유의 컨벤션·비표준 도구·과거의 실수만 남기고 나머지는 걷어내는 것이 오히려 낫다. 도구를 더 많이 설치하는 것과 도구를 잘 다루는 것은 다른 문제다.
이 글을 읽는 독자들도 지금 당장 MCP를 열 개씩 추가하거나 CLAUDE.md를 수백 줄로 늘리기보다는, 지금 쓰고 있는 도구가 어떤 원리로 동작하는지 한 번쯤 파고들어 보기를 권한다. 그게 생태계가 어떤 방향으로 흘러가든 흔들리지 않는 기반이 된다고 생각한다.
참고 자료
참고 자료
📚함께 읽으면 좋은 글
Harness(Systems) Engineering
2026. 6. 22. · 31 min read
이번 포스팅에서는 프롬프트 엔지니어링과 컨텍스트 엔지니어링, 그 다음에 대한 이야기를 해보려고 한다. 바로 앞 글인 토큰 절약법을 정리하면서 줄곧 머릿속을 떠나지 않던 질문이 하나 있었다. "개별적 프롬프팅에서 비우고 골라내는 기술(context engineering)로 무게중심이 옮겨가고 있다" 고 생각하는데, 글을 닫고 나니 자연스럽게 다음 질문이 따라...
토큰 절약법
2026. 6. 11. · 59 min read
이번 포스팅에서는 AI 토큰을 절약하는 방법에 대한 이야기를 해보려고 한다. 옛날에는 성능과 비용보다는 결과와 과정에 집중했다. AI가 산출한 결과물에 허점이 많다 보니 그것들을 검증해야 했고, 빠르게 결과물을 뽑아야 하다 보니 나를 비롯한 수많은 사람들이 토큰이 부족하면 결제하고 더 높은 구독제를 활용했다. 필자도 그랬다. (사실 처음 몇 달은 토큰 비용...
토큰의 원리
2026. 6. 10. · 30 min read
이번 포스팅에서는 AI 토큰이 도대체 무엇이고 어떤 원리로 동작하는지에 대한 이야기를 해보려고 한다. 필자는 그동안 AI 도구를 어떻게 잘 쓸지, 어떤 도구가 유행이고 왜 유행하는지를 주로 다뤄왔다. 그러다 토큰 절약법 글을 정리하면서 한 가지를 새삼 느꼈다. 비용을 줄이는 방법을 이야기하려면 결국 "토큰이 무엇이고 어떻게 청구되는가"를 먼저 알아야 하는데...